Статья на конкурс «био/мол/текст»: Это интересный вопрос, ответ на который должен был дать проект «Геном человека», завершившийся в 2003 году. После того как ученые получили основную информацию о геноме человека, они попытались определить число генов, но эта задача оказалось не такой простой. Цель настоящей статьи — суммировать и проанализировать научные данные по составлению каталога генов у человека.

Конкурс «био/мол/текст»-2018
Генеральный спонсор конкурса — компания «Диаэм»: крупнейший поставщик оборудования, реагентов и расходных материалов для биологических исследований и производств.
Спонсором приза зрительских симпатий выступил медико-генетический центр Genotek.
«Книжный» спонсор конкурса — «Альпина нон-фикшн»
Как же мало известно о генах! Первый раз я остро ощутила это, находясь на практике в лаборатории медицинской генетики Харбинского медицинского университета. Исследовательская группа, где я проходила стажировку, занималась изучением онкогена Sei-1, который индуцирует образование двухминутных хромосом (DM), что способствует развитию онкогенеза. Однако механизм образования онкогена Sei-1 остается неизвестным до сих пор. А ведь различные мутации генов являются причиной возникновения и других опасных заболеваний человека, помимо рака. Итак, в данной статье мы изложим некоторые соображения о том, почему мы все еще многое не знаем о генах, а также сформулируем наше мнение о том, сколько генов у человека.
Проект «Геном человека» и полный список генов

Рисунок 1. Арт-проект на выставке «Геном — расшифровка кода жизни» в Национальном музее естественной истории в Вашингтоне
Проект «Протеом человека»
«Протеом человека» является продолжением проекта «Геном человека». Предполагается, что благодаря проекту по изучению протеома мы узнаем точное количество белок-кодирующих генов, что впоследствии позволит понять, сколько всего генов у человека.
Немного о РНК
Проект «Геном человека» показал, что молекулы РНК также важны для жизни, как и ДНК. Внутри клеток существует множество РНК (рис. 2). Изначально РНК подразделяются на некодирующие РНК (нкРНК), которые не транслируются в белки, и кодирующие РНК (мРНК), служащие матрицей для синтеза полипептидных цепей белка. Некодирующие РНК имеют более сложную классификацию. Они бывают инфраструктурными и регуляторными. Инфраструктурные РНК представлены рибосомными РНК (рРНК) и транспортными РНК (тРНК). Молекулы рРНК синтезируются в ядрышке и составляют основу рибосомы, а также кодируют белки субъединиц рибосомы. После того, как рРНК полностью собраны, они переходят в цитоплазму, где в качестве ключевых регуляторов трансляции, участвуют в чтении кода мРНК. Последовательность из трех азотистых оснований в мРНК указывает на включение определенной аминокислоты в последовательность белка. Молекулы тРНК, приносят указанные аминокислоты на рибосомы, где синтезируется белок.
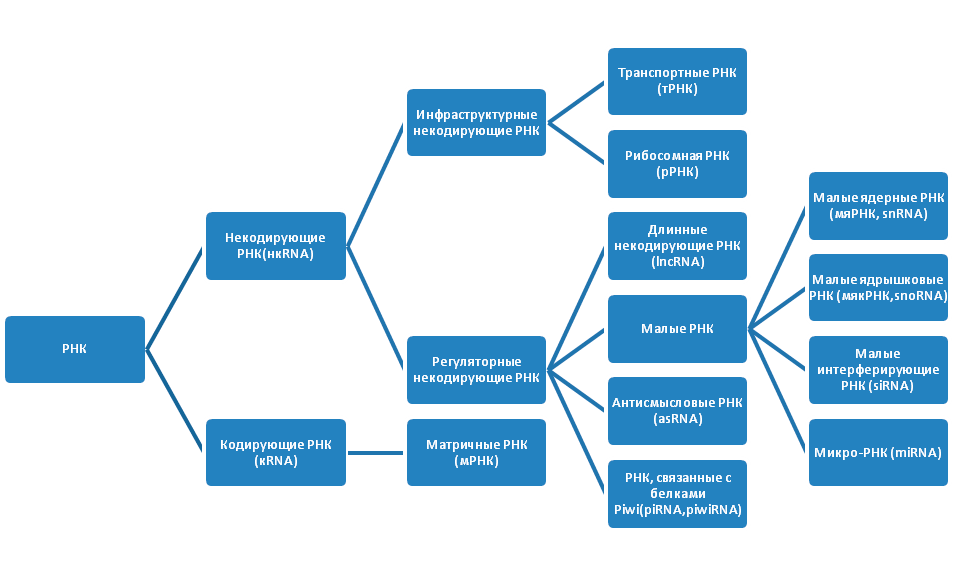
Рисунок 2. Виды РНК
рисунок автора статьи
Регуляторные нкРНК очень широко представлены в организме, классифицируются в зависимости от размера и выполняют ряд важных функций (табл. 1).
Проблема терминологии
Прежде чем ответить на вопрос: «Сколько у нас генов?», нужно понять, что же такое ген?
любой участок хромосомной ДНК, который транскрибируется в функциональную молекулу РНК или сначала транскрибируется в РНК, а затем транслируется в функциональный белок.
Это определение включает как гены некодирующих РНК, так и белок-кодирующие гены, и позволяет определять все варианты альтернативного сплайсинга в одном локусе как варианты одного и того же гена. Это позволяет исключить псевдогены – нефункциональные остатки структурных генов, утратившие способность кодировать белок.
Секвенирование нового поколения (NGS)
Благодаря NGS, базы данных днкРНК и других генов РНК (таких как микро-РНК) резко выросли за десятилетие, и текущие каталоги генов человека теперь содержат больше генов, кодирующих РНК, чем белки (табл. 2).

Рисунок 3. Последовательность ДНК, получаемая после секвенирования человеческого генома
В ходе секвенирования РНК обнаружилось, что альтернативный сплайсинг, альтернативное инициирование транскрипции и альтернативное прерывание транскрипции проиcходят гораздо чаще, чем полагали, затрагивая до 95% человеческих генов. Следовательно, даже если известно местоположение всех генов, сначала нужно выявить все изоформы этих генов, а также определить, выполняют ли эти изоформы какие-либо функции или они просто представляют собой ошибки сплайсинга.
Базы данных генов человека
Задача по составлению каталога всех генов по-прежнему не решена. Проблема заключается в том, что за последние 15 лет только две исследовательские группы составили список доминантных генов: RefSeq, которая поддерживается Национальным центром биотехнологической информации (NCBI) при Национальных институтах здоровья (NIH), и Ensembl/Gencode, которая поддерживается Европейской молекулярно-биологической лабораторией (EMBL). Однако, несмотря на большой прогресс, сейчас в каталогах различается количество белок-колирующих генов, генов длинных некодирующих РНК, псевдогенов, а также варьирует количество антисмысловых РНК и других некодирующих РНК (табл. 2). Каталоги еще дорабатываются: например, в прошлом году сотни генов, кодирующих белок, были добавлены или удалены из списка Gencode. Эти разногласия объясняют проблему создания полного каталога человеческих генов.
В 2017 году была создана новая база данных генов человека — CHESS. Примечательно, что она включает все белок-кодирующие гены как Gencode, так и RefSeq, так что пользователям CHESS не нужно решать, какую базу данных они предпочитают. Бóльшее количество генов может вызывать больше ошибок, но создатели считают, что бóльший набор окажется полезным при исследовании болезней человека, которые еще не отнесены к генетическим. Набор генов CHESS в настоящее время в версии 2.0 еще не окончательный, и, безусловно, создатели работают над его усовершенствованием.
Таким образом, все еще неизвестно, сколько всего генов у человека. Существует ряд проблем, затрудняющих эту задачу. Например, многие гены (особенно, гены днкРНК), видимо, имеют высокую тканеспецифичность. Из этого следует, что пока ученые подробно не исследуют все типы клеток человека, они не могут быть уверены, что обнаружили все человеческие гены и транскрипты. Безусловно, сегодня знания о человеческих генах стали значительно обширнее, чем в начале проекта «Геном человека», а технологии совершеннее. Это дает надежду на то, что в скором времени мы узнаем точный ответ на поставленный вопрос.
Это было семь лет назад — 26-го июня 2000 года. На совместной пресс-конференции с участием президента США и премьер-министра Великобритании представители двух исследовательских групп — International Human Genome Sequencing Consortium (IHGSC) и Celera Genomics — объявили о том, что работы по расшифровке генома человека, начавшиеся ещё в 70-х годах, успешно завершены, и черновой его вариант составлен. Начался новый эпизод развития человечества — постгеномная эра.
Что может дать нам расшифровка генома, и стоят ли потраченные средства и усилия достигнутого результата? Фрэнсис Коллинз (Francis S. Collins), руководитель американской программы «Геном человека», в 2000 году дал следующий прогноз развития медицины и биологии в постгеномную эру:
- 2010 год — генетическое тестирование, профилактические меры, снижающие риск заболеваний, и генная терапия до 25 наследственных заболеваний. Медсёстры начинают выполнять медико-генетические процедуры. Широко доступна преимплантационная диагностика, активно обсуждаются ограничения в применении данного метода. В США приняты законы для предотвращения генетической дискриминации и соблюдения конфиденциальности. Практические приложения геномики доступны не всем, особенно это чувствуется в развивающихся странах.
- 2020 год — на рынке появляются лекарства от диабета, гипертонии и других заболеваний, разработанные на основе геномной информации. Разрабатывается терапия рака, прицельно направленная на свойства раковых клеток определенных опухолей. Фармакогеномика становится общепринятым подходом для создания многих лекарств. Изменение способа диагностики психических заболеваний, появление новых способов их лечения, изменение отношения общества к таким заболеваниям. Практические приложения геномики все еще доступны далеко не везде.
- 2030 год — определение последовательности нуклеотидов всего генома отдельного индивида станет обычной процедурой, стоимость которой менее $1000. Каталогизированы гены, участвующие в процессе старения. Проводятся клинические испытания по увеличению максимальной продолжительности жизни человека. Лабораторные эксперименты на человеческих клетках заменены экспериментами на компьютерных моделях. Активизируются массовые движения противников передовых технологий в США и других странах.
- 2040 год — Все общепринятые меры здравоохранения основаны на геномике. Определяется предрасположенность к большинству заболеваний (ещё до рождения). Доступна эффективная профилактическая медицина с учетом особенностей индивида. Болезни определяются на ранних стадиях путем молекулярного мониторинга.Для многих заболеваний доступна генная терапия. Замена лекарств продуктами генов, вырабатываемыми организмом при ответе на терапию. Средняя продолжительность жизни достигнет 90 лет благодаря улучшению социо-экономических условий. Проходят серьезные дебаты о возможности человека контролировать собственную эволюцию.Неравенство в мире сохраняется, создавая напряженность на международном уровне.
Как видно из прогноза, геномная информация в недалеком будущем может стать основой лечения и профилактики множества болезней. Без информации о своих генах (а она умещается на стандарный DVD-диск) человек в будущем сможет вылечить разве что насморк у какого-нибудь целителя в джунглях. Это кажется фантастикой? Но когда-то такой же фантастикой была поголовная вакцинация от оспы или интернет (заметьте, в 70-х его еще не существовало)! В будущем генетический код ребенка будут выдавать родителям в роддоме. Теоретически, при наличии такого диска, лечение и предотвращение любых недугов отдельно взятого человека станет сущим пустяком. Профессиональный врач сможет в предельно сжатые сроки поставить диагноз, назначить эффективное лечение, и даже определить вероятность появления разных болезней в будущем. К примеру, современные генетические тесты уже позволяют точно определить степень предрасположенности женщины к раку груди. Почти наверняка, лет через 40–50 ни один уважающий себя врач без генетического кода не захочет «лечить вслепую» — подобно тому, как сегодня хирургия не может обойтись без рентгеновского снимка.
Давайте зададимся вопросом — а достоверно ли сказанное, или, может быть, в действительности всё будет наоборот? Смогут ли люди наконец победить все болезни и придут ли они ко всеобщему счастью? Увы. Начнем с того, что Земля маленькая, и счастья на всех не хватит. По правде сказать, его не хватит даже для половины населения развивающихся стран. «Счастье» предназначено в основном для государств, развитых в плане науки, в частности — наук биологических. Например методика, с помощью которой можно «прочесть» генетический код любого человека, уже давно запатентована. Это отлично отработанная автоматизированная технология — правда, дорогостоящая и очень тонкая. Хочешь, покупай лицензию, а хочешь — придумывай новую методику. Только вот денег на подобную разработку хватит далеко не у всех стран! В итоге ряд государств будет обладать медициной, существенно опережающей уровень остального мира. Естественно, в слаборазвитых странах Красным Крестом будут строиться благотворительные больницы, госпитали и геномные центры. И постепенно это приведет к тому, что генетическая информация пациентов развивающихся стран (которых большинство), сосредоточится у двух-трех держав, финансирующих эту благотворительность. Что можно сделать, имея такую информацию — даже представить трудно. Может, и ничего страшного. Однако возможен и другой исход. Битва за приоритет, сопровождавшая секвенирование генома, наглядно подтверждает важность доступности генетической информации. Давайте кратко вспомним некоторые факты из истории программы «Геном человека».
В американском городе Бетесда, что недалеко от Вашингтона, находится один из координационных центров HUGO (HUman Genome Organization). Центр координирует научную работу по теме «Геном человека» в шести странах — Германии, Англии, Франции, Японии, Китае и США. В работу включились учёные из многих стран мира, объединенные в три команды: две межгосударственные — американская Human Genome Project и британская из Wellcome Trust Sanger Institute — и частная корпорация из штата Мериленд, включившаяся в игру чуть позже, — Celera Genomics. Кстати, это пожалуй первый случай в биологии, когда на таком высоком уровне частная фирма соревновалась с межгосударственными организациями.
Борьба происходила с использованием колоссальных средств и возможностей. Как отмечали некоторое время назад российские эксперты, Celera стояла на плечах у программы «Геном Человека», то есть использовала то, что уже было сделано в рамках глобального проекта. Действительно, Celera Genomics подключилась к программе не сначала, а когда проект уже шёл полным ходом. Однако специалисты из Celera усовершенствовали алгоритм секвенирования. Кроме того, по их заказу был построен суперкомпьютер, который позволял складывать выявляемые «кирпичики» ДНК в результирующую последовательность быстрее и точнее. Конечно, все это не давало компании Celera безоговорочного преимущества, однако считаться с ней как с полноправным участником гонки заставило.

Широкая известность и масштабное финансирование — палка о двух концах. С одной стороны, за счет неограниченных средств работа продвигается легко и быстро. Но с другой стороны, результат исследований должен получиться таким, каким его заказывают. К началу 2001 года в геноме человека со стопроцентной достоверностью было идентифицировано больее 20 тыс. генов. Эта цифра оказалось в три раза меньше, чем было предсказано всего за два года до этого. Вторая команда исследователей из Национального института геномных исследований США во главе с Френсисом Коллинсом независимым способом получила те же результаты — между 20 и 25 тыс. генов в геноме каждой человеческой клетки. Однако неопределенность в окончательные оценки внесли два других международных совместных научных проекта. Доктор Вильям Хезелтайн (руководитель фирмы Human Genome Studies) настаивал, что в их банке содержится информация о 140 тыс. генов. И этой информацией он не собирается пока делиться с мировой общественностью. Его фирма вложила деньги в патенты и собирается зарабатывать на полученной информации, поскольку она относится к генам широко распространенных болезней человека. Другая группа заявила о 120 тыс. идентифицированных генов человека и также настаивала, что именно эта цифра отражает общее число генов человека.
Тут необходимо уточнить, что эти исследователи занимались расшифровкой последовательности ДНК не самого генома, а ДНК-копий информационных (называемых также матричными) РНК (иРНК или мРНК). Другими словами, исследовался не весь геном, а только та его часть, что перекодируется клеткой в мРНК и направляет синтез белков. Поскольку один ген может служить матрицей для производства нескольких различных видов мРНК (что определяется многими факторами: тип клетки, стадия развития организма и т. д.), то и суммарное число всех различных последовательностей мРНК (а это именно то, что запатентовала Human Genome Studies) будет значительно бóльшим. Скорее всего, использовать это число для оценки количества генов в геноме просто некорректно.
Очевидно, что наспех «приватизированная» генетическая информация будет в ближайшие годы тщательно проверяться, пока точное число генов станет, наконец, общепринятым. Но настораживает тот факт, что в процессе «познания» патентуется вообще все, что только можно запатентовать. Тут даже не шкура не убитого медведя, а вообще все, что находилось в берлоге, было поделено! Кстати, на сегодня дебаты сбавили обороты, и геном человека официально насчитывает только 21667 генов (версия NCBI 35, датированная октябрём 2005 года). Следует отметить, что пока большая часть информации всё-таки остаётся общедоступной. Сейчас существуют базы данных, в которых аккумулирована информация о структуре генома не только человека, но и геномов многих других организмов (например, EnsEMBL). Однако попытки получить исключительные права на использование каких-либо генов или последовательностей в коммерческих целях всегда были, есть сейчас и будут предприниматься впредь.

Рисунок 2. Слева: Автоматизированная линия подготовки образцов ДНК для секвенирования в Центре Геномных исследований института Уайтхеда. Справа: Лаборатория в Сэнгеровском институте, заполненная автоматами для высокопроизводительной расшифровки последовательностей ДНК.
Завершение расшифровки заняло еще несколько лет и привело почти что к удвоению стоимости всего проекта. Однако уже в 2004 г. было объявлено, что эухроматин прочитан на 99% с общей точностью одна ошибка на 100 000 пар оснований. Количество разрывов уменьшилось в 400 раз. Аккуратность и полнота прочтения стала достаточной для эффективного поиска генов, отвечающих за то или иное наследственное заболевание (например, диабет или рак груди). Практически это означает, что исследователям больше не надо заниматься трудоемким подтверждением последовательностей генов, с которыми они работают, так как можно полностью положиться на определенную и доступную каждому последовательность всего генома.
Другая задача, решение которой станет делом недалекого будущего, — определение последовательности оставшихся «малых» процентов генома, составляющих гетерохроматин, т. е. бедных генами и богатых повторами участков ДНК, необходимых для удвоения хромосом в процессе деления клетки. Наличие повторов делает задачу расшифровки этих последовательностей неразрешимой для существующих подходов, и, следовательно, требует изобретения новых методов. Поэтому не удивляйтесь, когда году в 2010 выйдет очередная статья, объявляющая об «окончании» расшифровки генома человека — в ней будет рассказано о том, как был «взломан» гетерохроматин.
Другую точку зрения можно проиллюстрировать, процитировав академика Кордюма В. А.:
Действительно, чтобы разумно пользоваться новой информацией, надо ее понимать. А для того чтобы понять геном — не просто прочитать, этого далеко не достаточно, — нам потребуются десятилетия. Слишком уж сложная картина вырисовывается, и чтобы осознать её, нам надо будет поменять многие стереотипы. Поэтому на самом деле расшифровка генома ещё продолжается и будет продолжаться. И будем ли мы стоять в стороне или станем, наконец, активными участниками этой гонки — зависит от нас.
Последний год жизни авторы этой статьи посвятили созданию инфраструктуры по получению, хранению и анализу кода жизни — генетической информации, которая записана в молекуле ДНК. Что такое ДНК с точки зрения математика, каковы основные принципы построения компьютерной архитектуры для анализа огромных массивов генетической информации и что ждать в будущем от тотальной прозрачности и доступности теперь уже и нашего индивидуального кода жизни, — обо всём этом расскажет предлагаемая вашему вниманию статья.
В своей знаменитой книге «Что такое жизнь с точки зрения физики?» Э. Шрёдингер описывал живую клетку с происходящими в ней процессами как динамическую систему, находящуюся в стационарном состоянии при неизменности внешних факторов. За прошедшие 65 лет с момента написания этой книги изменилось само представление о клетке и о том, как она реагирует на быстро меняющиеся условия обитания. На передний план вышли уже не те вещества, которыми клетка обменивается с окружающей средой в состоянии динамического равновесия, а информационные потоки, определяющие её развитие, рост и смерть в существенно неравновесных условиях. На смену биохимии пришли молекулярная биология и биоинформатика. Мы вплотную подошли к следующему эпохальному труду под названием «Что такое жизнь с точки зрения математики?», который терпеливо ждёт своего талантливого автора.
Сегодня все знают, что информация, необходимая оплодотворённой яйцеклетке, чтобы развиться сначала в эмбрион, а потом и во взрослый организм, записана в молекулах ДНК, последовательность нуклеотидных остатков в которой можно представить в виде текста. В этом тексте, как и в любом другом, самое важное — это последовательность букв (в ДНК их, как известно, всего четыре). Совокупность всех молекул ДНК ядра клетки (каждая из которых, взаимодействуя с белками, образует отдельные хромосомы) называют ядерным генóмом (митохондрии, бывшие в незапамятные времена свободноживущими микроорганизамами, имеют свой собственный геном). К примеру, бактерии, обитающие у нас в кишечнике и помогающие переваривать пищу, имеют геном длиной порядка нескольких миллионов букв. Простая вошь — уже 500 миллионов, а геном человека составляет более трех миллиардов букв. Для сравнения, все четыре тома «Войны и мира» Толстого содержат около двух миллионов букв, — т. е., примерно эквивалентны генетической информации бактерии, а геном человека можно сравнить со всей библиотекой Толстого в Ясной Поляне. (С другой стороны, объём кинофильма в формате Blu-ray уже существенно превосходит размер генома, — так что говорить нужно, конечно, не только об объёме информации, но и о её «качестве».)
Читать — не перечитать
Современная геномная лаборатория — например, Лаборатория геномики в Курчатовском Институте в Москве, — способна за один день «начитать» последовательность длиной до 20 миллиардов нуклеотидов. Что же касается стоимости таких работ, — прочтение одного человеческого генома уже подешевело почти до 10 000 долларов, — т. е., за 10 лет цена упала на 6 порядков (в миллион раз!). По оценкам экспертов, ценовой рубеж, когда персональная геномика войдёт в жизнь каждого из нас через медицину, страховки, работодателей и через прочие социальные институты, составляет 1000 долларов за индивидуальный геном. По всей видимости, он будет достигнут в ближайшие 5 лет.
Таким образом, теоретически можно ожидать, что через несколько лет каждый из нас будет обладателем 5 Гб информации о себе (именно столько занимают 3 миллиарда нуклеотидов в «четырехзначном исчислении», плюс служебные данные). Как хранить, анализировать и защищать эту важнейшую персональную информацию? Что она значит для жизни человека XXI века? Какие возможности и риски следует рассматривать в контексте обладания 5 Гб информации каждым из 6 миллиардов жителей Земли ?
Видимо, следует сделать оговорку — каждым из 6 миллиардов, достаточно обеспеченным, чтобы позволить себе тратить деньги на такие «пустяки». — Ред.