Геномика. Информатика для биологов
Автор сообщества Фанерозой, биотехнолог, Людмила Хигерович.

На дворе двадцать первый век, стремительными темпами информационные технологии захватывают все больше сфер нашей жизни, включая науку. С каждым годом они все глубже проникают в различные отрасли науки, способствуя их развитию и порождая новые, смежные дисциплины. Таковой, например, является геномика.
Точной даты рождения геномика не имеет. Однако ее появление относят к 1980-м годам, незадолго после открытия структуры ДНК и начала распространения методов секвенирования. Некоторые ученые, правда, все же указывают год рождения геномики — 1977, год полной расшифровки генома бактериофага Φ-X179.
Вероятно, тут стоит притормозить и добавить парочку словарных справок под спойлер. Не все наши читатели хорошо знакомы с терминами, а некоторые уже успели позабыть.
Базовая “буква” генетической информации, основа генетического кода, химически происходящая из азотистого основания. Всего существует 4 нуклеотида — аденин, гуанин, цитозин и тимин. При синтезе РНК тимин замещается на урацил.
Совокупность всего генетического материала организма, особи. В некоторых случаях говорят о геноме популяции или даже вида, имея в виду их совокупное генетическое разнообразие.
Участок ДНК (у некоторых вирусов — РНК), содержащий информацию об определенном полипептиде (аминокислотной цепочке, в перспективе превращающейся в белок), или функциональной РНК (например, транспортной РНК, доставляющей аминокислоты). В классическом понимании, ген — участок ДНК, отвечающий за определенный признак или функцию, однако с открытием полифункциональности белков этот подход устарел.
Участок ДНК, не содержащий информацию о белке или служебной РНК, но несущий регуляторные функции. В интронах содержатся сигналы начала и конца репликации, точки посадки ферментов и условия разблокировки синтеза определенных веществ (например, лактозный оперон у бактерий, включающийся только при условии недостатка глюкозы и избытка лактозы в среде).
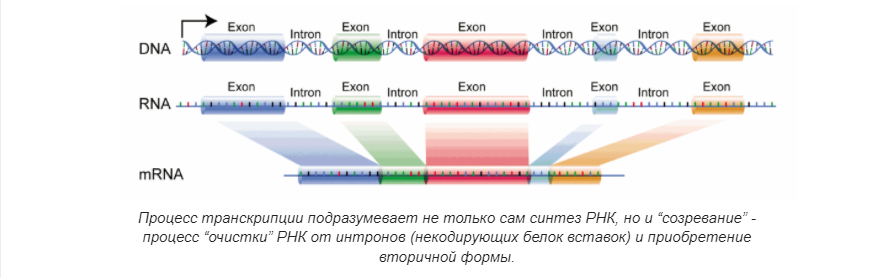
Процесс переноса информации с ДНК на РНК по принципу комплементарности (соответствия нуклеотидов). Синтезированная РНК в дальнейшем “созревает”, превращаясь в матричную или информационную (мРНК/иРНК, становится основой синтеза белка), транспортную (тРНК, переносит аминокислоты к месту синтеза белка), служебную/ферментную (фРНК, РНК-энзимы или рибозимы, катализаторы биохимических реакций), рибосомальную (рРНК, учавствует в образовании субъединиц рибосом), транспортно-матричную (тмРНК, помогает при “застревании” элементов синтеза белка и бактерий и в пластидах), и другие редкие виды.
Процесс синтеза белка путем “прочтения” информации с мРНК и “перевода” ее на “язык” аминокислот. При этом учитывается правило триплетов (кодонов) — одну аминокислоту кодирует последовательность из трех нуклеотидов. Некоторые аминокислоты одновременно кодируют несколько триплетов.
Цепная молекула, состоящая из последовательно соединенных аминокислотных остатков. После синтеза пептиды проходят сложные преобразования — “созревают”, превращаясь в протеины и белки (функциональные молекулы) или соединяясь с другими синтезированными веществами, образуя структурные элементы клетки (например, рибосомы, мембранные порты), а также участвуя в других процессах.
Совокупность всего транскрипционного материала (белков и РНК), формирующих организм и фенотип особи.
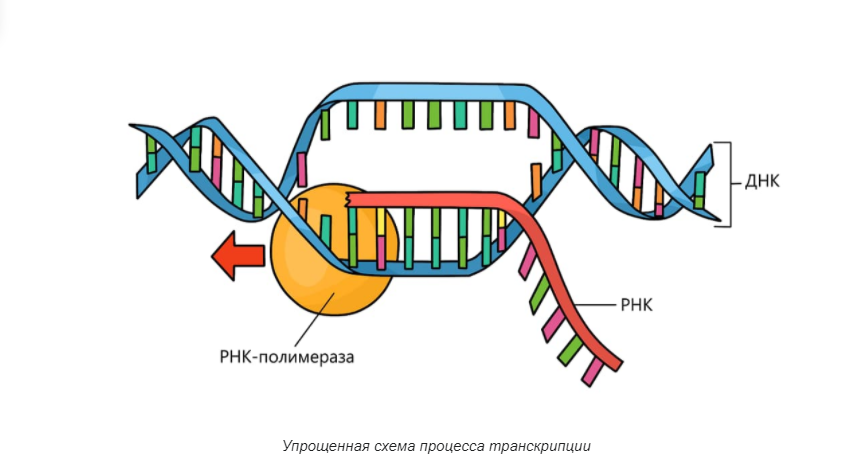
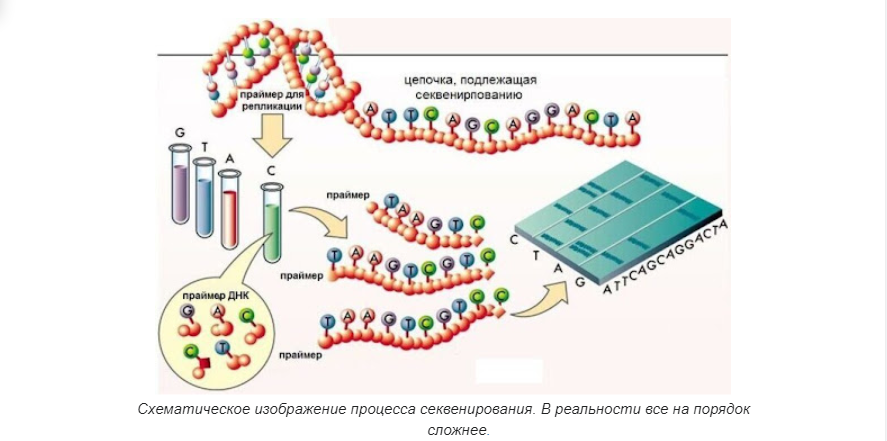
Процесс расшифровки или прочтения генетической информации. В основе его лежит ряд сложных химических реакций, в ходе которых ДНК очищают, “распутывают” и “разрезают” на относительно короткие кусочки для анализа их нуклеотидной последовательности. Существуют разные методики и техники секвенирования, и даже способы анализа состава ДНК без разрезания или путем многократного повторения определенных кусочков (полимеразная цепная реакция, или ПЦР-амплификация).
Повторение — мать учения. Итак, как мы говорили выше, геномика — это междисциплинарная область биологии, в которой основное внимание уделяется структуре, функциям, эволюции, картированию и редактированию геномов. Геном — это полный набор ДНК организма, включая все его гены, а также его иерархическую трехмерную структурную конфигурацию. В отличие от генетики, которая относится к изучению отдельных генов и их роли в наследовании, геномика направлена на коллективную характеристику и количественную оценку всех генов организма, их взаимосвязей и влияния на организм.
Почему геномика — важный раздел науки?
Гены могут управлять производством белков, с помощью ферментов и молекул-мессенджеров. В свою очередь, белки составляют структуры тела, такие как органы и ткани, а также контролируют химические реакции и передают сигналы между клетками. Геномика также включает в себя секвенирование и анализ геномов с использованием высокопроизводительного секвенирования ДНК и биоинформатики для сборки и анализа функции и структуры целых геномов. Достижения в области геномики вызвали революцию в исследованиях, основанных на открытиях, и в системной биологии, чтобы облегчить понимание даже самых сложных биологических систем, таких как мозг.
Эта область знаний также включает исследования внутригеномных (внутри генома) явлений, таких как эпистаз (влияние одного гена на другой), плейотропия (один ген влияет на более чем один признак), гетерозис (сила гибрида) и другие взаимодействия между локусами и аллелями внутри генома.

Чем больше люди изучали генетический аппарат живых организмов, тем становилось яснее, что усилий одного только человеческого мозга недостаточно для полноценного анализа и расшифровки. Так что как только появилась возможность машинного анализа, биологи с радостью поручили часть своей работы компьютерам. Так зародилась другая междисциплинарная область знаний — биоинформатика.
Биоинформатика — часть науки, объединяющая в себе генетику, биохимию и молекулярную биологию, математическую статистику и отчасти задевающую краем эволюционную и популяционную биологии, медицину и математическую статистику. Биоинформатики является междисциплинарным полем, которое разрабатывает методы и программные средства для понимания биологических данных, в частности, когда наборы данных являются большими и сложными. Как междисциплинарная область науки, биоинформатика сочетает в себе биологию, информатику, информационную инженерию, математику и статистику для анализа и интерпретации биологических данных. Биоинформатика использовалась для анализа in silico (на компьютере) биологических запросов с использованием математических и статистических методов.
Некоторые соотносят биоинформатику с геномикой, однако они не перекрывают друг друга полностью — скорее, геномика пользуется достижениями биоинформатики, и в то же время сама является инструментом ее пополнения и расширения.
Разделы геномики
За почти пятьдесят лет своего существования геномика значительно расширилась и приобрела внутреннюю структуру — разделилась на несколько направлений, тем не менее, все еще зависящих друг от друга. Деление это весьма условно, многие отделы не просто пересекаются, а значительно перекрывают друг друга.

Геномику подразделяют на следующие направления:
- Структурная геномика
- Функциональная геномика
- Сравнительная геномика
- Музеогеномика
- Когнитивная геномика
- Вычислительная геномика
Структурная геномика — самый крупный и самый “развитый” раздел. Ее задача — выяснение конечной структуры белка, закодированного в исследуемой последовательности. Это важно при расшифровке генетической информации: мало выяснить, какие основания и как расположены в участке ДНК, гораздо более интересно, во что она транскрибируется.
И этот интерес отнюдь не праздный — состав и структура белка могут многое сказать о его функции и месте в метаболизме.

После синтеза аминокислотная цепочка (первичная структура) “плавает” в цитоплазме, и сворачивается в петли. Когда подходящие участки белка сближаются, в дело вступают молекулярные химические силы — некоторые места “слипаются” под действием сил водородных связей, ионных связей, а также сил Ван-дер-Ваальса, образуя вторичную объемную структуру — альфа-спираль и бета-лист. На этом их преобразование не останавливается — в конечном итоге белок приобретает форму глобулы — плотно свернутого клубка. В таком виде он обычно и существует, выполняя свои функции.
Знание третичной структуры позволяет сделать предположение о функциях белка — это не просто комок аминокислот, глобула устроена так, что у нее есть домены — участки с разным предназначением. Условно их делят на основную часть и функциональную — например, ферментирующая ямка (энзимы и пищеварительные ферменты), “хвост” для закрепления на мембране (кинезины, мембранные белки), участки, “примагничивающиеся” к другим белкам (актино-миозиновый комплекс в мышцах) и т. д.
Этому даже посвящен значительный раздел биоинформатики — он так и называется, предсказание структуры белка (protein structure prediction). Это преимущественно математическое моделирование с опорой на молекулярную биологию и химию. Помимо расшифровки первичной структуры, необходимо учитывать две важные вещи — количество свободной энергии и нахождение глобального минимума энергии. Это звучит, как магическая формула, однако на практике это то, от чего зависит, как и насколько преобразуется и свернется белок. Кроме того, требуются огромные вычислительные мощности для расчета всех возможных вариантов пространственной структурой белка — а это миллионы вариантов для белка длиной в сотню аминокислотных остатков. Круг поиска несколько сужают методы предсказания укладки (альфа-спираль или бета-лист, и участки с повышенной вероятностью “слипания”) и гомологическое (сравнительное) моделирование, основанное на знании о структуре хорошо изученных белков. В то же время его осложняют возможные посттранскрипционные преобразования — белок не просто меняет свою пространственную структуру, но также может распадаться, разрезаться ферментами, сшиваться и приобретать конечные свойства только в четвертичной структуре — в комплексе с другим белком.
Помимо этого, структурная геномика в комплексе с функциональной может предсказывать болезни, возникающие при генетических аномалиях. Так, было выяснено, что мутация в одном из белков мембраны клеток может вызывать иммунитет организма к ВИЧ СПИДу, но при этом ослабляет его перед ОРВИ и лихорадкой западного Нила. Этот же белок отчасти ответственен за тип вашего темперамента — гипертимный ли, флегматичный и т. д. Эта часть соотносится с функциональной геномикой.

Функциональная геномика своей основной задачей ставит прослеживание полного пути реализации генома. Она показывает, как определенный ген превращается в белок, и какой конечный признак в организме от него зависит, чем приближается к протеомике — междисциплинарной отрасли науки, изучающей структуру и функции протеинов и белков в частности. Это весьма сложно в рамках многоклеточного организма, так как один и тот же белок выполняет множество функций. Кроме того, разные белки могут одновременно влиять на один и тот же признак.
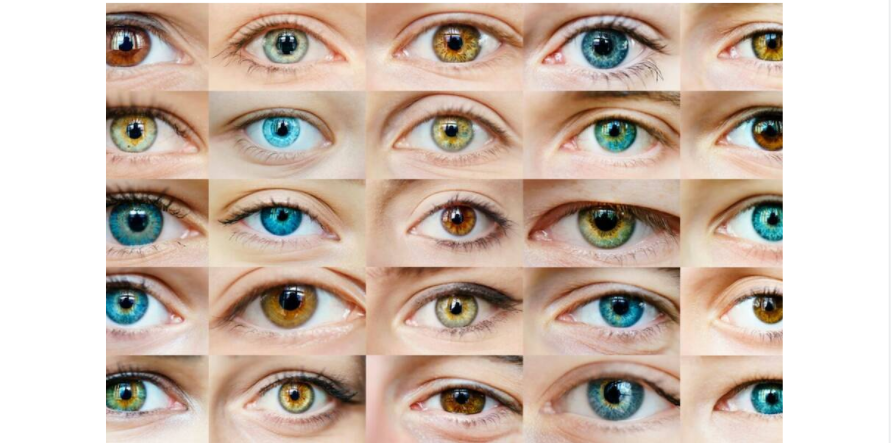
Так, например, цвет глаз человека кодируют как минимум 6-8 генов на 2-3 хромосомах. За светлые глаза в основном отвечает мутация гена OCA2. За синий или зелёный цвет отвечает ген EYCL1 хромосомы 19; за коричневый — EYCL2; за коричневый или синий — EYCL3 хромосомы 15. Кроме того, с цветом глаз связаны гены OCA2, SLC24A4, TYR, влияющие на оттенки и переходные цвета. Все эти гены, вернее, их белки, действуют одновременно, благодаря чему найти два одинаковых рисунка радужки почти невозможно. Кроме того, в зависимости от перенесенных заболеваний, питания и выцветания на солнце цвет глаз меняется в течении всей жизни, что еще больше осложняет работу по составлению статистических исследований.
Сравнительная геномика близка к эволюционной биологии и популяционной генетике. Она сравнивает организацию и функционирование генома у разных систематических групп организмов, изучает их принципиальные сходства и различия, и ищет аналогию между ними. Значительную часть составляет поиск гомологий и аналогий у разных организмов с геномом человека — вопрос больше практический, чем праздный. От этого зависит выбор организма для производства лекарственных средств или даже выращивания органов и тканей для трансплантации. Так, многие фармацевтические препараты, а также витамины производят с помощью бактерий, так как их генетический аппарат почти не преобразует конечный продукт, и при этом обладает достаточным функционалом для синтеза. Ну и, конечно, их относительно легко модифицировать и культивировать.
Музеогеномика — во многом схожа со сравнительной. Только специализируется на исследовании генома музейных экспонатов — палеонтологических, зоологических, ботанических и других. Она позволяет установить степень родства вымерших таксономических групп, проследить эволюцию признака у ископаемых растений и даже предположить, какие животные были предыдущими носителями вирусов и прочих паразитов. Кроме того, музеогеномика позволяет проследить токсигенное влияние человека, сравнивая образцы столетней давности с сегодняшними обитателями Земли.

Когнитивная геномика. Несколько странное направление в контексте современных исследований. Казалось бы, человечество еще в прошлом веке пережило предрассудки о наследовании характера и умственных способностей и связи этого с внешностью. Однако полностью отрицать влияние генетики на мозговую активность — тоже неправильно. Белковый состав мембран нервных клеток, а также степень и качество миелинизации (образования изолирующих оболочек) оказывает сильное влияние на тип нервной системы и темперамент.
Гиперактивность и повышенная эмоциональность раздражимость детей связана, в том числе с образованием миелиновых оболочек — у детей практически нет изоляции между отдельными нервными клетками, из-за чего возбуждение в одной моментально передается в соседний, и далее по цепочке. Это явление называется иррадиация. Разумеется, она сохраняется и у взрослых, однако значительная ее часть “гасится” изолирующими прослойками.
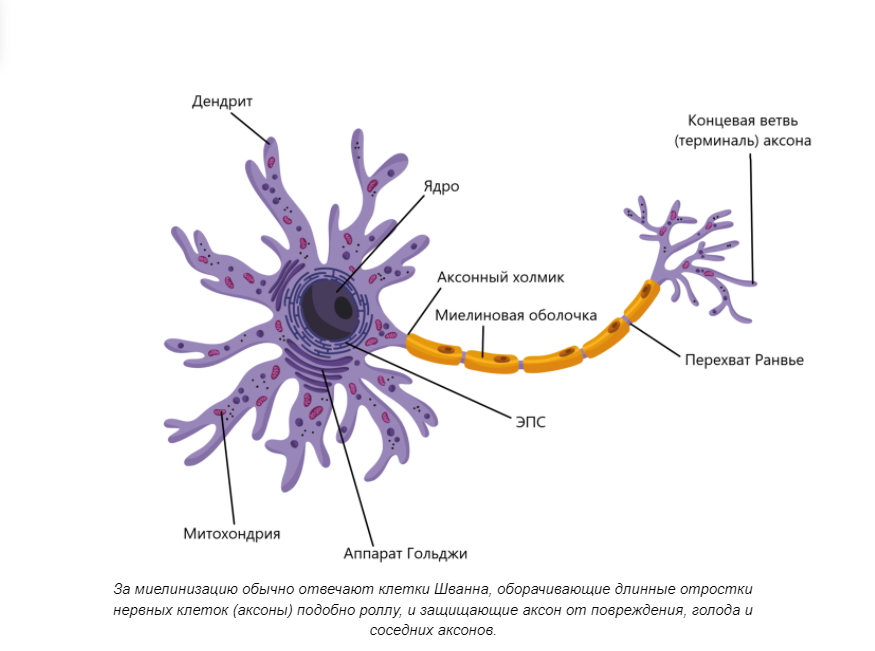
Темперамент человека зависит от типа нервной системы, что в свою очередь зависит от состава и количества мембранных белков, структура которых закодирована в ДНК — по оценке Вайнбергера, примерно 70% всех генов организма оказывает влияние на нервную систему, в частности на головной мозг. С возрастом, разумеется, на темперамент оказывает влияние опыт, физиологические преобразования и воспитание, что формирует вторичные структуры — характер и личность. Однако базовые параметры так или иначе заложены генетически.
В рамках когнитивной отлично уживаются элементы сравнительной геномики. Ученые сравнивают геномы нескольких видов, чтобы выявить генетические и фенотипические различия между ними. Наблюдаемые фенотипические характеристики, связанные с высшей нервной деятельностью, включают поведение, личность, нейроанатомию и невропатологию. Теория когнитивной геномики основана на элементах генетики, эволюционной биологии, молекулярной биологии, когнитивной психологии, поведенческой психологии и нейрофизиологии.
Но когнитивная геномика не ставит своей задачей узнать, кто родился с большим шансом стать гением, а кто с меньшим. В первую очередь когнитивная геномика работает с выявлением причин патологий высшей нервной деятельности и аномалий мозга, а также исследует возможные способы их лечения или уменьшения. Большинство поведенческих или патологических фенотипов происходят не из-за мутации только одного гена, а из-за сложной генетической основы. Однако есть некоторые исключения из этого правила, такие как болезнь Гентингтона, которая вызвана одним конкретным генетическим заболеванием. На возникновение нейроповеденческих расстройств влияет целый ряд факторов, генетических и негенетических. Методы когнитивной геномики были использованы для изучения генетических причин многих психических и нейродегенеративных расстройств, включая синдром Дауна, большое депрессивное расстройство, аутизм и болезнь Альцгеймера.
Вычислительная геномика — самая близкая к биоинформатике часть, родившаяся и развивающаяся одновременно с ней. Так или иначе, ее элементы используют все остальные разделы геномики. Ее основа — вычислительный анализ, позволяющий расшифровать не только отдельные участки или гены, но охватить геном целиком, включая не только последовательность нуклеотидов в ДНК, но и синтезированную на ее основе РНК.
Геномика и Big Data
Геном даже одного простейшего организма состоит из тысяч или даже десятков тысяч пар оснований. Анализ одной только цепочки ДНК из одной хромосомы “вручную” занимает годы, если не десятилетия. Прибавим к этому то, что секвенирование зачастую предполагает разрезание ДНК на маленькие кусочки, и получим еще одну задачку — собрать расшифрованные кусочки в нужном порядке. Эта задача, называемая генетическим картированием, поистине титаническая. И хоть без человеческого умственного труда все равно не обойтись при финальном сведении данных и написании вывода, то значительную часть аналитического труда выполняет компьютер.
Специально для целей геномики даже были разработаны особые программные и иерархические средства анализа. Так, например, были разработаны специфические «конвейеры» анализа, неоднократно “прогоняющие” одну и ту же последовательность, а затем повторяющие эти же процедуры с другой, в конечном итоге сравнивая полученные результаты и фиксируя сходства и различия. Обычно это используется для идентификации генов-кандидатов (изменения в них могут вызвать онкологию) и однонуклеотидных полиморфизмов (точечных мутаций, характеризующихся многократным, идущим подряд повторением основания на одной из цепей, что вызывает разрыв между цепями).
Компьютерный анализ также помогает при аннотировании — маркировании генов. Этот процесс необходимо автоматизировать, потому что большинство геномов слишком велики для аннотирования вручную, не говоря уже о необходимости аннотировать как можно больше геномов, поскольку скорость секвенирования перестала быть проблемой. Аннотации стали возможными благодаря тому факту, что гены имеют узнаваемые начальные и конечные области (промоторы и терминаторы, имеющие зачастую схожий или одинаковый состав у разных групп организмов), хотя точная последовательность, обнаруженная в этих областях, может варьироваться между генами.
Первое описание комплексной системы аннотации генома было опубликовано в 1995 году командой Института геномных исследований, которая выполнила первое полное секвенирование и анализ генома свободноживущего организма, бактерии Haemophilus influenzae. Оуэн Уайт разработал и построил систему программного обеспечения для идентификации генов, кодирующих все белки, РНК переноса, рибосомных РНК (и других сайтов — функциональных частей), а также для выполнения начальных функциональных назначений. Большинство современных систем аннотации генома работают аналогичным образом, но программы, доступные для анализа геномной ДНК, такие, как программа GeneMark, обучены и используются для поиска генов, кодирующих белок, у Haemophilus influenzae, постоянно меняются и улучшаются.
Кроме аннотирования и анализа отдельного генома, технологии Big data позволяют массово сравнивать геномы особей в популяциях и даже видов. Так появилась, например, вычислительная эволюционная биология. Эволюционная биология — это изучение наследственности, изменчивости и происхождения видов, а также их изменения с течением времени. Информатика помогла эволюционным биологам, позволив исследователям:
- Отслеживать эволюцию большого числа организмов, измеряя изменения в их ДНК, а не только с помощью физической систематики или физиологических наблюдений
- Сравнивать целые геномы, что позволяет изучать более сложные эволюционные события, такие как дупликация генов, горизонтальный перенос генов, а также предсказывать факторы, важные для видообразования бактерий
- Построение сложных вычислительных моделей популяционной генетики для прогнозирования результатов работы системы с течением времени
- Отслеживать и обмениваться информацией о все большем количестве видов и организмов.
В перспективе это поможет составить более подробное и правдоподобное филогенетическое дерево — т. н. древо жизни, отражающее примерную эволюцию живого.
Сейчас существует несколько вариантов филогенетического древа. Хотя древом его назвать теперь сложно — скорее, это куст, причем далеко не всегда имеющий общий корень. Кроме того, эти схемы разнятся в зависимости от того, какой признак мы ставим во главу угла.

Такие сложности возникают потому, что в процессе эволюции ДНК не только усложняется, но и упрощается, теряя “ненужные” участки в ходе делеций или отбора. Кроме того, существует такое явление, как горизонтальный перенос генов — обмен участками генома между генетически неродственными группами. Так, например, значительная часть интронов у бактерий, растений и животных, включая человека, — это следы заражения вирусами, которые потеряли часть своего генома, ответственную за синтез оболочки вируса и репликацию.
В рамках вычислительной геномики существует также такое понятие, как Интерактом (Interactome) или сети молекулярного взаимодействия. В двух словах, это совокупность локализаций и взаимодействий конкретной молекулы в рамках одной конкретной клетки. Такая модель также может описывать наборы непрямых взаимодействий между генами. Молекулярные взаимодействия могут происходить между молекулами, принадлежащими к разным биохимическим семействам (белки, нуклеиновые кислоты, липиды, углеводы и т. д.), а также внутри каждого семейства. Когда такие молекулы связаны физическими взаимодействиями, они образуют сети молекулярных взаимодействий, которые обычно классифицируются по природе задействованных соединений. Чаще всего, интерактом относится к сети межбелкового взаимодействия (PPI) (PIN) или ее разновидностям.
Это чрезвычайно сложная схема, реализация которой была бы невозможна без компьютерного моделирования. Она настолько сложна технически и важна практически, что в последнее время выделяется в самостоятельную область биоинформатики.
Биоинформатика для всех
Помимо решения сложных узкопрофильных задач, для которых обычно создаются специальные программные методы, существуют и более широкого спектра сервисы.
Так, есть ряд проектов, призванных помочь любому желающему провести быстрый анализ полученного сиквенса или белка — рано или поздно с такой проблемой сталкивается любой биолог-исследователь.
Первым подобным проектом стал алгоритм Нидлмана — Вунша на основе динамического программирования. Он был создан для того, чтобы сравнить наборы последовательностей аминокислот друг с другом при использовании матриц замен, полученных в более раннем исследовании М. Дейхофф.

Позже появился алгоритм BLAST, который позволяет осуществлять быстрый и оптимизированный поиск в базах данных последовательностей генов. BLAST и его модификации — одни из наиболее широко используемых алгоритмов для этой цели.
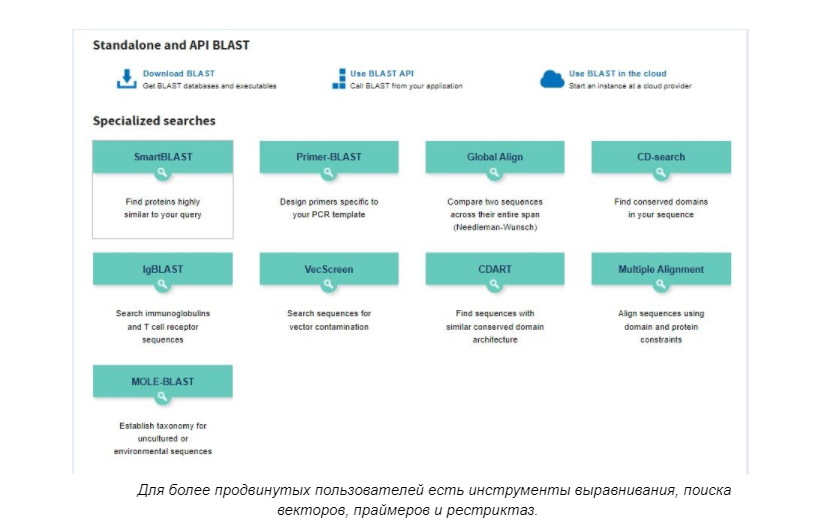
Примерно теми же функциями обладают и системы UGENE и DNAStar, однако пользование ими для обычного человека затруднено, к тому же есть платные пакеты с расширенным функционалом. Кроме того, существуют различные сервисы по моделированию возможной структуры белков. Таковым является, например, Google DeepMind.
На этом мы завершим очередную мини-экскурсию в мир биологической информатики или информативной биологии. Надеемся, что вы сегодня узнали что-то новое и интересное.
Всего хорошего и не болейте!

Lesk AM (2017). Introduction to Genomics (3rd ed.). New York: Oxford University Press. p. 544.
Dong Xu, Lukasz Jaroszewski, Zhanwen Li, Adam Godzik. AIDA: ab initio domain assembly for automated multi-domain protein structure prediction and domain–domain interaction prediction (англ.) // Bioinformatics. — 2015-07-01. — Vol. 31, iss. 13. — P. 2098—2105.
Plomin, R. & Spinath, F.M. (2004). «Intelligence: Genetics, Genes, and Genomics.» Journal of Personality and Social Psychology, 86(1): 112—129
.
Sulem P., Gudbjartsson D. F., Stacey S. N., et al. Genetic determinants of hair, eye and skin pigmentation in Europeans (англ.) // Nat. Genet.: journal. — 2007. — December (vol. 39, no. 12). — P. 1443—1452.
Gonnet G. H. 2012. Surprising results on phylogenetic tree building methods based on molecular sequences. BMC Bioinformatics, 13:148
Google’s DeepMind predicts 3D shapes of proteins, The Guardian. 2018
Hug, L., Baker, B., Anantharaman, K. et al. A new view of the tree of life. Nat Microbiol 1, 16048 (2016).
Julian Vosseberg, Jolien J. E. van Hooff, Marina Marcet-Houben, Anne van Vlimmeren, Leny M. van Wijk, Toni Gabaldón & Berend Snel. Timing the origin of eukaryotic cellular complexity with ancient duplications // Nature Ecology and Evolution. 2020. DOI: 10.1038/s41559-020-01320-z.
Papanikolaou, N.; Pavlopoulos, G.A.; Theodosiou, T.; Iliopoulos, I. Protein-protein interaction predictions using text mining methods (англ.) // Methods: journal. — 2015. — Vol. 74. — P. 47—53.
Mikhail Fursov, Olga Golosova, Konstantin Okonechnikov. Unipro UGENE: a unified bioinformatics toolkit (англ.) // Bioinformatics. — 2012-04-15. — Vol. 28, iss. 8. — P. 1166—1167.
Wang L, Eftekhari P, Schachner D, Ignatova ID, Palme V, Schilcher N, Ladurner A, Heiss EH, Stangl H, Dirsch VM, Atanasov AG. Novel interactomics approach identifies ABCA1 as direct target of evodiamine, which increases macrophage cholesterol efflux. Sci Rep. 2018 Jul 23;8(1):11061.
Kotlyar M, Pastrello C, Pivetta F, Lo Sardo A, Cumbaa C, Li H, Naranian T, Niu Y, Ding Z, Vafaee F, Broackes-Carter F, Petschnigg J, Mills GB, Jurisicova A, Stagljar I, Maestro R, Jurisica I (2015). «In silico prediction of physical protein interactions and characterization of interactome orphans». Nature Methods. 12 (1): 79–84.
Robson JF, Barker D (October 2015). «Comparison of the protein-coding gene content of Chlamydia trachomatis and Protochlamydia amoebophila using a Raspberry Pi computer». BMC Research Notes. 8 (561): 561.
Dawson WK, Maciejczyk M, Jankowska EJ, Bujnicki JM (July 2016). «Coarse-grained modeling of RNA 3D structure». Methods. 103: 138–56.
Великая Отечественная война закончилась 75 лет назад. Эта война изменила ход мировой истории, судьбы людей и карту мира. Наш народ противостоял мощному натиску высокоорганизованного и хорошо вооружённого противника — нацистской Германии и её союзников. Мы выстояли и победили. Наша задача — сохранить память о подвиге народа, который своим единством и сплочённостью, трудолюбием и самоотверженностью, невероятной любовью к Родине обеспечил нам мир, свободу и независимость. День Победы — это праздник, объединяющий поколения. Мы помним свою историю и гордимся ею!
12 января 1722 года в соответствии с Именным Высочайшим Указом Петра I Правительствующему Сенату в России появился институт прокурорского надзора.
С тех пор наше государство претерпело немало реформ и изменений, однако прокуратура неизменно занимала уникальное положение в его структуре, а прокуроры всегда стояли на страже законности.
В данной рубрике представлены материалы, посвященные истории органов прокуратуры с эпохи Петра I и до наших дней.
Знание прав и обязанностей, умение отстоять свои интересы законным способом необходимо каждому человеку. Выполняя важную государственную задачу, органы прокуратуры участвуют в работе по правовому просвещению и правовому информированию населения. Данный раздел содержит разъяснения действующих нормативных правовых актов, судебной практики, информацию об изменениях федерального и регионального законодательства.
Пользователи, имеющие учётную запись на Портале государственных услуг Российской Федерации, могут при помощи мобильного приложения не только направить обращения, а также отследить статус его рассмотрения в личном кабинете на портале.
В официальном мобильном приложении предусмотрены следующие полезные сервисы:
– Единый реестр проверок;
– Сводный план проверок юридических лиц и индивидуальных предпринимателей;
– Сводный план проверок органов государственной власти субъектов Российской Федерации и их должностных лиц;
– Часто задаваемые вопросы.
Также в приложении можно найти образцы заявлений и документов и контактную информацию с привязкой к геолокации.
Кроме того, в мобильном приложении можно знакомиться с актуальными новостями о деятельности органов и организаций прокуратуры Российской Федерации и получать push-уведомления.


Термины генодиагностики
Дата обновления: 12 октября 2022
Дата публикации: 9 июня 2022
ДНК(Дезоксирибонуклеиновая кислота) – молекула, обеспечивающая хранение, передачу из поколения в поколение и реализацию генетической информации, записанной в ней. В клетках эукариот (в т.ч. человека) ДНК находится в ядре клетки в составе хромосом.
Нуклеотид -единичное звено молекулы ДНК. Существуют четыре типа нуклеотидов, сочетание которых формирует нуклеотидную последовательность ДНК: А (аденин), G (гуанин), Т (тимин), C (цитозин).
Хромосома– последний уровень упаковки ДНК. В норме в каждой человеческой клетке 46 хромосом: 2 из которых половые хромосомы (XX у женщин и XY у мужчин) и аутосомы (все остальные).
Ген – упрощенно: участок ДНК, в котором закодирована информация о строении одной молекулы белка или фермента.
Аллели– различные формы одного и того же гена, определяющие альтернативные варианты одного белка. Все гены, находящиеся в аутосомах, представлены двумя аллелями, один из которых унаследован от отца, а другой – от матери.
Генетический полиморфизм – сосуществование в популяции двух и более аллельных форм одного гена, находящихся в динамическом равновесии в течение нескольких поколений. Наиболее часто встречаются однонуклеотидные полиморфизмы (SNP от single nucleotide polymorphism) – замена одного нуклеотида на другой в конкретной точке гена.
Генотип – здесь: комбинация аллелей одного гена. Различают гомозиготный и гетерозиготный генотип.
Гомозиготный генотип – генотип, содержащий одинаковые аллели одного гена.
Гетерозиготный генотип – генотип, содержащий разные аллели одного гена.
Фенотип – совокупность проявлений генотипа (общий облик организма), в узком смысле – отдельные признаки, контролируемые определёнными генами. Фенотип формируется на основе взаимодействия генотипа и факторов внешней среды.
Фактор риска – фактор, повышающий вероятность развития болезни или травмы. Различают генетические (наследственно-обусловленные) и негенетические (средовые, поведенческие и др.) факторы риска.
Мультифакториальные заболевания – болезни, которые развиваются в результате взаимодействия определённых генетических факторов и специфических воздействий факторов окружающей среды. При этом наличие неблагоприятных аллелей одного или нескольких генов не является абсолютно фатальным для определения исхода, они лишь определяют индивидуальный уровень предрасположенности к заболеванию.
Генетическая предрасположенность – обусловленная генетическим полиморфизмом склонность к развитию заболевания при воздействии на организм факторов риска.
Общепопуляционный риск – среднестатистическая вероятность развития заболевания для населения данного региона.
Индивидуальный риск – вероятность развития заболевания для жителя данного региона с учетом его генотипа. Если индивидуальный риск выше популяционного, то вероятность развития заболевания возрастает, особенно при воздействии факторов риска.
Генная сеть – группа координировано-работающих генов, контролирующих выполнение определенной функции организма.
Что такое Полный геном и зачем он нужен
Атлас запустил новый продукт — Полный геном. Теперь мы можем исследовать не только отдельные точки в геноме, как в генетическом тесте, но и прочитать всю последовательность нуклеотидов генома. В этой статье рассказываем, что это и зачем это нужно.
Внимание! Мы подарим Полный геном одному из наших читателей, кто выполнит все задания. Подробнее — в конце статьи.

Что значит Полный геном?
Чтобы разобраться с полным геномом или полногеномным секвенированием (whole genome sequencing, WGS), мы сначала расскажем коротко о технологии обычного генетического теста.
Микрочип и обычный генетический тест
Генетический тест «Атлас», как и многие подобные тесты, делают с помощью ДНК-микрочипа (DNA-microarray, Beadchip). Поверхность ДНК-микрочипа содержит множество небольших углублений (порядка 700 тысяч), в каждом из которых находится по кремниевому шарику диаметром около 3 микрометров. На поверхности этого шарика находятся сотни тысяч сшитых с ним идентичных коротких последовательностей одноцепочечной ДНК, соответствующих участку генома человека, расположенному рядом с исследуемой вариацией (снип, SNV). Каждый шарик соответствует только одной генетической вариации, а координаты лунки на чипе для каждого шарика известны (Рисунок 2D).
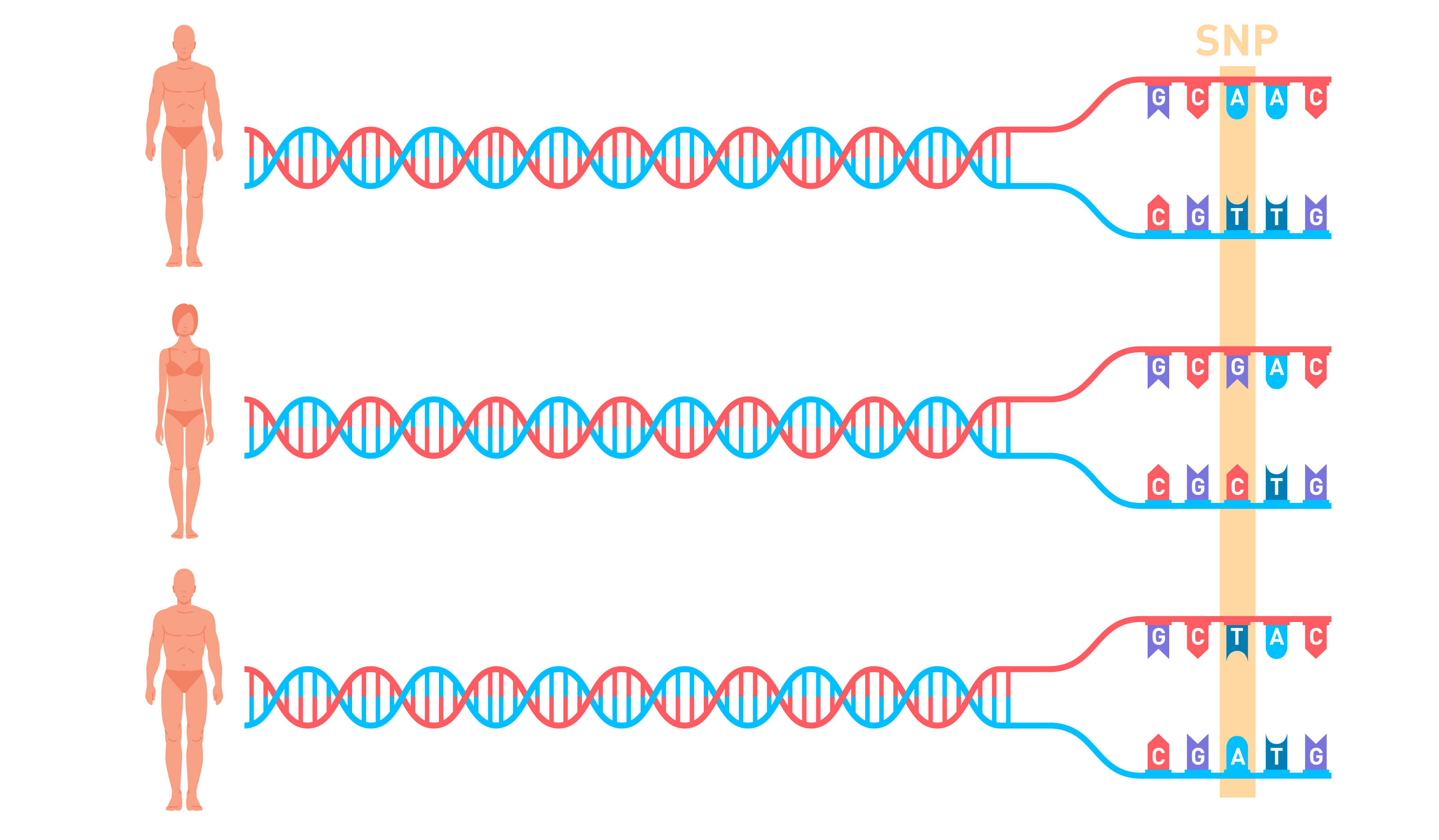
Рисунок 1 Автор иллюстраций Rentonorama
Например, полиморфизм rs4481887, который находится на первой хромосоме рядом с геном обонятельного рецептора OR2M7, имеет три аллеля: A, G и T. Наличие аллеля А на одной или на обеих хромосомах (генотипы A/G, A/T и A/A) определяет чувствительность к запаху мочи после употребления спаржи. При отсутствии аллеля А человек даже не будет догадываться о том, что после поедания спаржи с мочой выделяется вещество с характерным запахом.
Индел или INDEL (Insertion/Deletion) — другой тип генетических вариаций, в который относят удаление или вставку одного или нескольких нуклеотидов. Снипы и инделы вместе, наряду с возможными структурными изменениями: большими делециями, инсерциями, транслокациями, инверсиями, являются фактической разницей в геноме разных людей.
При сдаче генетического теста «Атлас» из слюны выделяют геномную и митохондриальную ДНК, увеличивают количество ее копий (амплифицируют) и фрагментируют — нарезают на небольшие отрезки (Рисунок 2А). Многочисленные одноцепочечные фрагменты человеческой ДНК соединяются с соответствующими им последовательностями на кремниевых шариках (Рисунок 2В), после чего происходит удлинение этих последовательностей на 1 искусственный флюоресцирующий нуклеотид (Рисунок 2С). Разные нуклеотиды светятся разными цветами: красным и зеленым. По соотношению интенсивностей свечения каждого цвета (Рисунок 2E) можно определить генотип, который соответствует шарику.
После сканирования всего чипа мы получаем около 700 тысяч генотипов вариаций и пропускаем их через нашу систему интерпретации. Часто пользователи пытаются сравнить результаты разных тестов, но замечают сильную разницу. Это происходит по нескольким причинам. Во-первых, разные компании используют разные версии чипов и наборы SNV. Как следствие, на одних чипах существуют уникальные наборы вариаций, которые нельзя найти на других чипах. Во-вторых, всегда существует ошибка генотипирования, которая может возникнуть по разным причинам, хотя она вносит наименьший вклад в различие результатов. Данные исследований показывают, что точность генотипирования на ДНК-микрочипах, которые использует Атлас, выше 99,5%. Но основная причина отличий результатов генетических тестов в интерпретации: разные компании делают ее по-разному даже для одинаковых исходных данных генотипирования.
Что такое полногеномное секвенирование?
Главное отличие полногеномного секвенирования от генотипирования на микрочипах — технология и обработка получаемых данных. При полногеномном секвенировании определяется почти вся последовательность ДНК. Почти — потому, что в геноме существуют участки, которые в силу различных причин невозможно прочитать. Часто это участки теломер и центромер — концов и центра хромосом. Для определения последовательностей подобных регионов генома используют малодоступные узкоспециализированные технологии. Такие исследования носят в основном исследовательский характер.
Определение последовательности ДНК позволяет узнать генотипы вариаций в любом месте генома, включая исследуемые вариации на ДНК микрочипе в генетическом тесте «Атлас». Для быстрого и эффективного определения последовательности генома используется технология NGS (next generation sequencing, секвенирование следующего поколения). Существует несколько принципиально отличающихся методов, созданных разными компаниями.
Суть метода Атласа заключается в следующем: выделенную и очищенную ДНК многократно амплифицируют и фрагментируют до определенной длины. К каждому фрагменту пришиваются специальные последовательности, которые позволяют управлять данным фрагментом. Прочитываются, именно эти обработанные фрагменты (Рисунок 3).
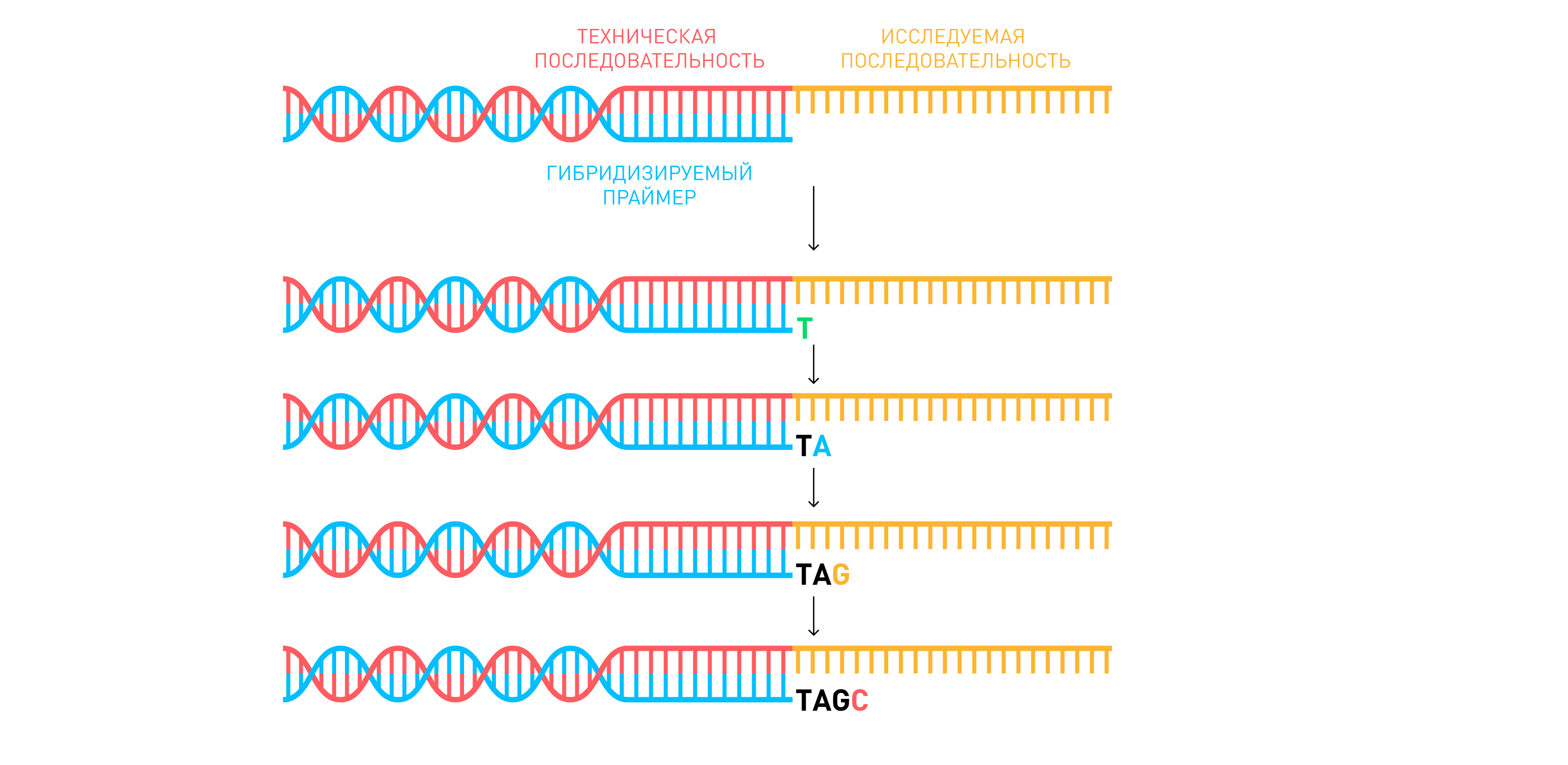
Рисунок 3. Процесс пошагового секвенирования: каждый следующий нуклеотид флуоресцирует в уникальном для него цветовом канале.
На каждом шаге происходит удлинение на один нуклеотид, с которым связан флуоресцентный зонд. Каждый из четырех нуклеотидов связан с зондом определенного цвета. Таким образом, шаг за шагом по цвету свечения можно определить порядок нуклеотидов в исследуемом фрагменте. Полученные последовательности каждого фрагмента называются прочтениями или ридами (reads), и их получается около 1 миллиарда на каждый образец исследуемой ДНК. Риды и показатели качества их прочтения хранятся в текстовом формате FASTQ.
Далее риды выравниваются (картируются) на референсный геном. С использованием специального программного обеспечения, например Burrows-Wheeler aligner, для каждого рида происходит поиск места на референсном геноме, которому он соответствует. Прочтение вместе с информацией о положении в геноме записывается в файл формата SAM или BAM. Визуализация картированных на геном ридов в SAM (BAM) файле с помощью геномного браузера IGV показана на Рисунке 4.
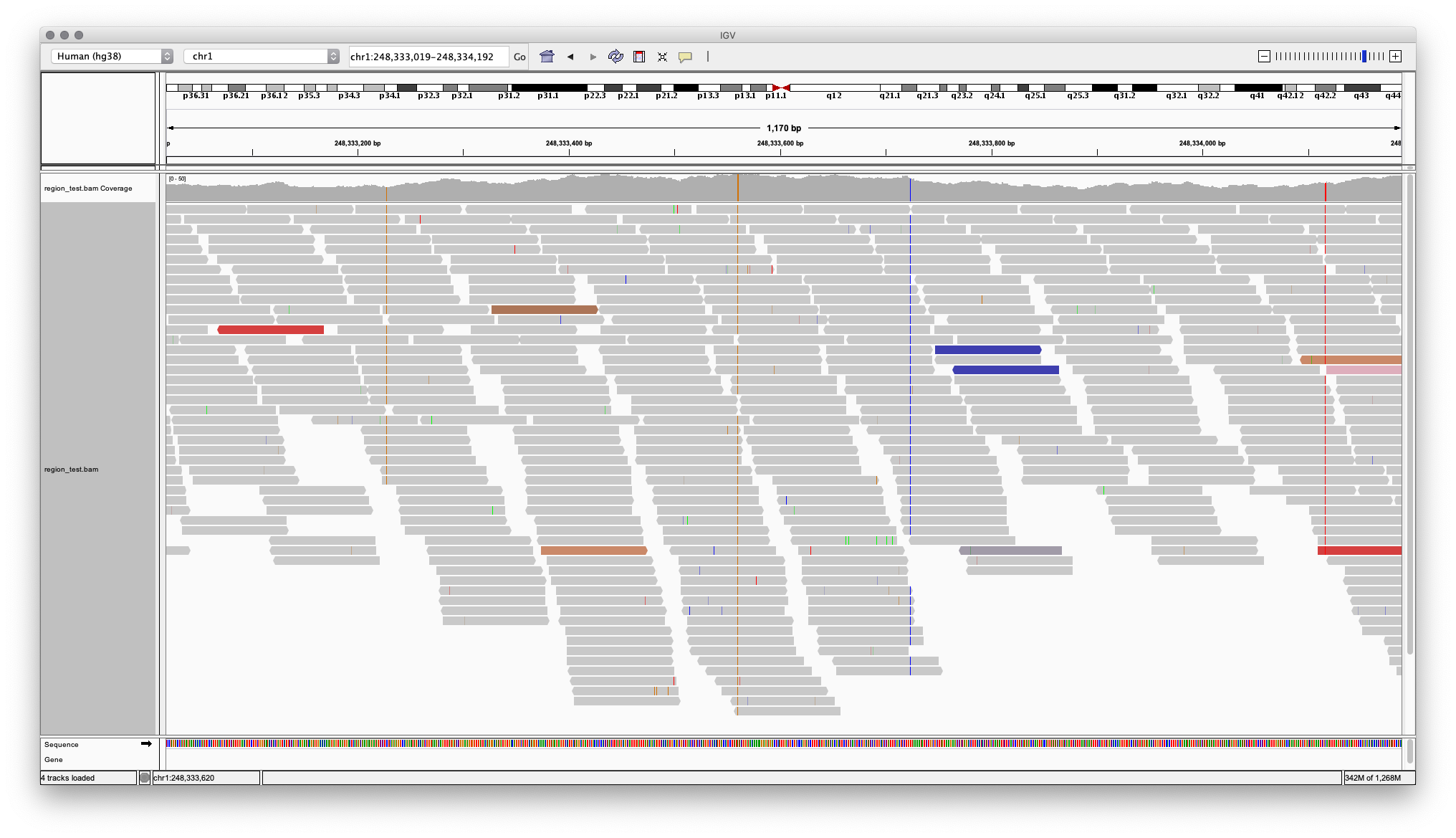
Рисунок 4. Визуализация BAM файла в программе IGV (участок хромосомы одного человека). Картированные риды обозначены горизонтальными блоками, позиция указана в треке сверху.
На рисунке также видно, что такое глубина прочтения (depth of coverage) — когда, любую позицию в референсном геноме покрывает несколько выровненных ридов. Значение усредняется по всему геному и используется как показатель качества исследования. Атлас гарантирует среднее покрытие генома глубиной выше 30, что обеспечивает высокое качество генотипирования. Увеличение глубины прочтения значительно увеличивает стоимость секвенирования, точность определения генетических вариаций и используется в узких онкологических исследованиях, например, в Атлас Онкодиагностике.
Образовательный блок 2
Референсный геном — это искусственно собранная последовательность ДНК биологического вида. Большинство последовательностей, из которых собран референсный геном человека, были взяты у одного человека Африкано-Европейского происхождения. Референсный геном регулярно обновляется: последняя версия, GRCh38, была выпущена в 2013 году и содержит в себе 3,3 млрд нуклеотидов. Несмотря на доступность новой версии, многие генетические тесты и сервисы по анализу генетических данных используют предыдущую — GRCh37. Для предоставления наиболее точных результатов анализа Атлас использует версию GRCh38.
Полученные после картирования файлы (SAM-файлы, sequencing alignment map, или в бинарном виде BAM — binary alignment map) фильтруются и используются для поиска вариаций в геноме, включая как однонуклеотидные вариации, так и короткие инсерции и делеции. Наличие однонуклеотидного варианта на хромосоме 1 в позиции 248333561 (приведенный ранее пример rs4481887 — вариант, определяющий чувствительность к запаху мочи после употребления спаржи) показано на Рисунке 5.
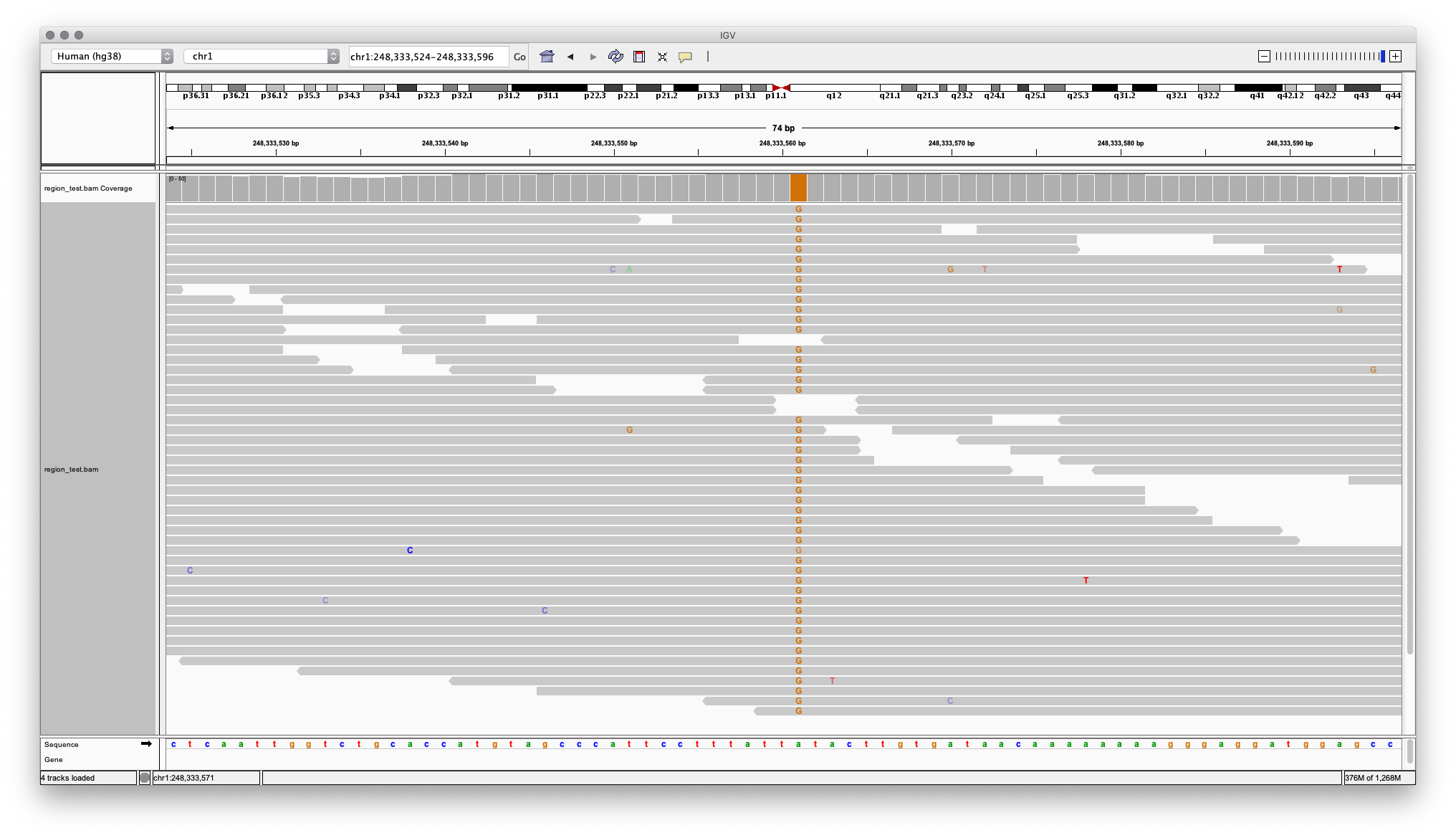
Рисунок 5. Визуализация BAM файла в программе IGV. Участок хромосомы 1. В позиции 248333561 находится полиморфизм rs4481887: нуклеотид в данной позиции не соответствует референсному геному и выделен цветом. Во всех ридах, которые покрывают данный участок генома, присутствует нуклеоид G, что говорит о гомозиготности генотипа. У человека с такими результатами секвенирования будет генотип G/G и нечувствительность к запаху мочи после употребления спаржи.
Найденные генетические вариации хранятся в VCF файле (variant call format). Он содержит обнаруженные аллели для каждой позиции генома, а также показатели качества генотипирования. VCF файл фильтруется: из него удаляются записи о наличии/отсутствии вариаций, которые не соответствуют порогам качества и являются потенциально ложными. Каждой найденной вариации присваиваются известные по ней данные из dbSNP, в частности, уникальные идентификаторы rsID.
Подробно ознакомиться со спецификой форматов хранения данных секвенирования и генотипирования можно по следующим ссылкам:
FASTQ — maq.sourceforge.net
SAM — samtools.github.io
VCF — samtools.github.io
Для визуализации картирования ридов (SAM или BAM файлов) используется различное программное обеспечение. Наиболее популярным является IGV (Integrative Genomics Viewer от Broad Institute). Загрузить IGV и ознакомиться с ним можно по ссылке.
Какие данные интерпретирует Атлас?
Полный геном содержит данные по тем вариантам генов, которые есть в генетическом тесте «Атлас», а также по признакам, которые нельзя подсчитать с помощью технологии генотипирования с использованием ДНК-микрочипов. Например, к таким признакам относятся риски онкологических заболеваний.
Здоровье
383 Наследственных заболеваний
Основной акцент всех тестов Атласа — раздел здоровье, и наш новый тест «Полный геном» не стал исключением. К признакам нашего основного теста мы добавили еще 65 наследственных заболеваний.
К наследственным или моногенным заболеваниям относятся болезни, которые передаются от родителей детям и на развитие которых не влияет образ жизни человека. Для развития такого заболевания достаточно мутации от одного или от обоих родителей в зависимости от типа наследования заболевания.
21 Многофакторное заболевание
На развитие многофакторных заболеваний влияют гены, образ жизни и факторы окружающей среды. К таким болезням относятся, например, сахарный диабет, ожирение, болезнь Паркинсона и Альцгеймера, атопический дерматит. В личном кабинете пользователю доступен расчет относительного риска развития заболевания на основе данных теста и опросника об образе жизни.
6 других признаков, связанных со здоровьем
Здесь мы собрали признаки, которые влияют на образ жизни человека. Например, продолжительность сна, хронотип, синдром хронической усталости, боязнь боли.
Клиническая генетика
43 Онкологических риска
Благодаря тому, что в полном геноме исследуется больше вариантов генов, мы получаем больше данных и можем оценить риски развития онкологических заболеваний. По результатам теста мы оцениваем предрасположенность к наследственным онкологическим синдромам.

53 Показателей восприимчивости к активным компонентам лекарств
Каждый человек по разному реагирует на лекарства: у одних препарат действует хорошо, другие страдают от тяжелый побочных эффектов, а у третьих лечение оказывается неэффективным. В некоторых случаях это обусловлено работой генов, которые влияют на метаболизм активных веществ и риски побочных реакций.
Например, препарат Омепразол снижает секрецию соляной кислоты в желудке. Используется при лечении язвенной болезни желудка и двенадцатиперстной кишки, рефлюксной болезни. Ген CYP2C19 кодирует фермент, который отвечает за метаболизм омепразола. Поэтому, в зависимости от вариантов гена, необходимо корректировать дозу омепразола или использовать альтернативное лекарственное средство.
В тесте мы исследуем варианты генов, связанные с особенностями метаболизма 53 препаратов. Среди них есть антидепрессанты, гормональные контрацептивы, препарат для снижения свертываемости крови и некоторые другие.
Специализированный отчет по наследственным заболеваниям
Отчет — заключение Лаборатории клинической биоинформатики Федора Коновалова. Биоинформатики лаборатории ищут носительство рецессивных заболеваний. Такое носительство чаще всего не влияет на здоровье человека, но у его будущих детей оно может привести к заболеванию. Также лаборатория может выявить уникальную, нигде ранее не описанную мутацию и дать по ней заключение, является ли она вероятно патогенной.
Эксперты проводят тщательный анализ актуальной научной информации о мутациях и заболеваниях в каждом конкретном случае. В заключении содержится вся необходимая информация для врача-генетика. С этим отчетом вы сможете обратиться к профильному специалисту в случае необходимости.
Такие генетические отчеты похожи на юридический документ с обилием сложных терминов, правильно оценить который может только специалист, в нашем случае — генетик. Поэтому мы не показываем данные клинической генетики до консультации. Во время встречи врач-генетик подробно рассказывает, на что стоит обратить внимание с учетом вашей семейной истории и наличия симптомов. Это может помочь, например, для уточнения возраста начала скрининга определенных заболеваний или при планировании семьи.
Питание
28 Отчетов
По генетическим тестам и даже по полному геному подобрать оптимальное питание и составить рацион нельзя. Продуктов, их способов приготовления и блюд настолько много, что исследователям трудно найти какие-либо корреляции с вариантами генов. При этом некоторые данные все же есть.
По определенным вариантам генов мы можем узнать, есть ли у человека предрасположенность к непереносимости лактозы или глютена, быстро или медленно организм справляется с алкоголем или кофеином, а также оценить предрасположенность к определенному уровню железа, кальция, омега-3 и 6 жирных кислот. По этим данным человек может решить, какие продукты ему стоит убрать или наоборот добавить в рацион.
Спорт
16 Отчетов
Определить вид спорта, который вам больше подходит генетически — так же сложно, как и подобрать питание. Видов физической нагрузки сейчас множество, и понятие спорт с каждым годом расширяется. Так скейтбординг и серфинг добавили в программу олимпийских видов спорта. Видов физической нагрузки слишком много, чтобы это в большей степени было обусловлено генетикой. Поэтому не верьте генетическим тестам, которые обещают найти наиболее подходящий вам вид спорта. Выбирайте тот вид спорта, который просто нравится.
Научные сообщества генетиков обеспокоены, что родители делают генетические тесты детям, чтобы узнать, какой вид спорта им больше подходит. В таком случае ребенка могут отправить в группу, которая ему не нравится, но подходит по результатам теста. Если человек хочет добиться выдающихся результатов в спорте, то успех в большей степени будет зависеть от его амбиций, силы воли и характера. Варианты генов тут играют меньшую роль.
С помощью генетического теста можно узнать, как гены влияют на риски спортивных травм, количество свободного инсулиноподобного фактора роста-1, уровень эритроцитов, эритропоэтина, а также на особенности обмена аминокислот — валина, лейцина и L-карнитина. К результатам «Полного генома» мы добавили также риск невралгии седалищного нерва, уровень IGFBP‑3, объем выдоха и другие.
Другие признаки
15 Отчетов
В этом разделе мы собрали признаки, которые относятся к особенностям организма: черты внешности, восприятие света, чувствительность к травам и запахам. В нашем тесте вы не найдете признаков, которые связаны с эмоциями, поведением или характером. В основном эти черты зависят от особенностей воспитания, окружения и привычек, и в меньшей степени на них влияют варианты генов. К тому же многие личные качества можно поменять или выработать во взрослом возрасте.
Происхождение
3 Отчета
Генетики не используют понятия этнической или национальной принадлежности. В большей степени они обусловлены культурными различиями, а не разными вариантами генов. Вместо этого генетики используют понятие популяция — группа людей, которая долгое время живет на одной территории. Сегодня доступны геномные данные определенных популяций, из них ученые выделили последовательности и варианты генов, характерные для каждой. Генетические исследования происхождения — это поиск таких вариантов в геноме и определение генетической схожести с известными популяциями в процентном соотношении.
Кроме популяционного состава по генетическому коду можно узнать свою гаплогруппу. Гаплогруппа — это группа людей с одинаковым вариантом гена, который случился у одного общего предка тысячи лет назад. Также по геному можно определить процент ДНК неандертальца. В геноме современного человека оказалось около 1–4 % ДНК неандертальцев. Сейчас известно только несколько признаков, которые зависят от наличия вариантов гена неандертальца, — рост волос на спине и уровень липопротеинов низкой плотности ЛПНП (плохой холестерин).

Сравнение Полного генома и генетического теста «Атлас»
Почему Полный геном?
Главный плюс Полного генома в том, что вы получаете всю информацию о своей ДНК. Когда появятся новые данные, мы просто добавим их в личный кабинет. С обычным генетическим тестом это работает не всегда, так как в нем исследуется около 660 000 вариантов — 0,1% всей ДНК. Для интерпретации новых признаков их может быть недостаточно.
Результаты теста помогут предпринять меры по профилактике заболеваний, планированию семьи, а врач сможет уточнить диагноз в будущем или уже сейчас. Тест доставят на дом и всё, что требуется от пользователя — собрать образец слюны и вызвать курьера для передачи пробирки в лабораторию.
Основа Полного генома «Атласа»: генетический анализ высокой точности (99,5%), контроль качества полученных данных, запатентованная система интерпретации данных, доступ к исходным данным, консультация генетика, а также отобранные научные статьи, которые доступны каждому пользователю. Всё это пользователь получает за 94 500 — самая низкая цена за подобные услуги в России. Тест уже можно купить на сайте Атласа.
Если вы умеете работать с большими данными, а особенно биоинформатическими, ваши сырые данные полного генома могут быть пластилином, с которым на досуге можно поиграть и узнать о себе больше. Например, можно отсеять варианты генов, которые изучают другие компании и загрузить в их базу интерпретации, узнать родственную связь с другим человеком, взять референсную ДНК шимпанзе или Неандертальца и сравнить насколько вы схожи.
А еще
Атлас приготовил большой подарок читателям Хабра! В следующих статьях мы дадим 3 задачи с примерами и вводными данными, а также информацией по необходимому ПО. Первый, кто решит все задачи, — получит Полный геном в подарок!