Как известно, в социальной сети ВКонтакте имеются ограничения для незарегистрированных пользователей, касающиеся большинства возможностей сайта, включая внутреннюю систему поиска. В рамках данной статьи мы расскажем о максимально действенных методах обхода ограничений подобного рода.
Пару дней назад получил тестовое задание от компании на вакансию Front-end dev. Конечно же, задание состояло из нескольких пунктов. Но сейчас речь пойдет только об одном из них — организация поиска по странице. Т.е. банальный поиск по введенному в поле тексту (аналог Ctrl+F в браузере). Особенность задания была в том, что использование каких-либо JS фреймворков или библиотек запрещено. Все писать на родном native JavaScript.
(Для наглядности далее буду сопровождать всю статью скринами и кодом, чтоб мне и вам было понятнее, о чем речь в конкретный момент)
Почему скрипт работал некорректно?
Все просто. Скрипт работает следующим образом. Сперва в переменную записываем все содержимое тега body, затем ищем совпадения с регулярным выражением (задает пользователь при вводе в текстовое поле) и затем заменяем все совпадения на следующий код:
А затем заменяем текущий тег body на новый полученный. Разметка обновляется, меняются стили и на экране подсвечиваются желтым все найденные результаты.
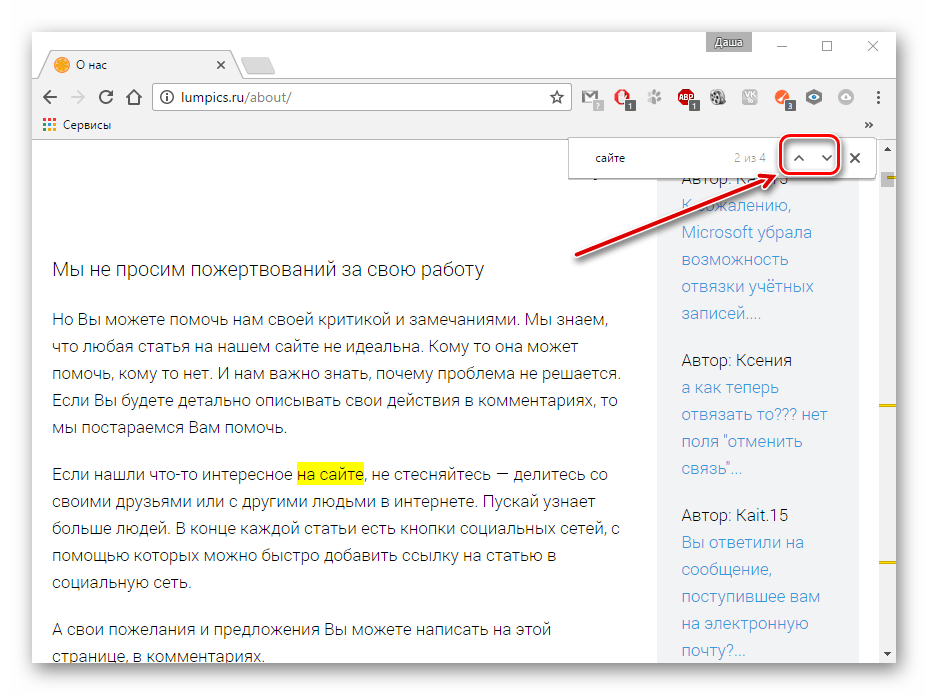
Вы уже наверняка поняли, в чем проблема, но я все же объясню подробней. Представьте, что в поле поиска ввели слово «div». Как вы понимаете, внутри body есть множество других тегов, в том числе и div. И если мы всем к «div» применим стили, указанные выше, то это уже будет не блок, а непонятно что, так как конструкция ломается. В итоге после перезаписи разметки мы получим полностью сломанную веб-страницу. Выглядит это так.
Было до поиска: Просмореть полностью
Стало после поиска: Просмореть полностью
Как видите, страница полностью ломается. Короче говоря, скрипт оказался нерабочим, и я решил написать свой с нуля, чему и посвящается эта статья.
Те, кто давно занимается поисковой оптимизацией, хорошо знают об операторах расширенного поиска Google. Например, почти все знают об операторе site:, который ограничивает поисковую выдачу одним сайтом.
Большинство операторов легко запомнить, это короткие команды. Но уметь эффективно их использовать — совсем другая история. Многие специалисты знают основы, но немногие по-настоящему овладели этими командами.
В этой статье я поделюсь советами, которые помогут освоить поисковые операторы для 15 конкретных задач.
- Поиск ошибок индексации
- Поиск незащищённых страниц (не https)
- Поиск дубликатов контента
- Поиск нежелательных файлов и страниц на своём сайте
- Поиск возможностей для гостевой публикации
- Поиск страниц со списками ресурсов
- Поиск профилей в социальных сетях
- Поиск возможностей для внутренних ссылок
- Поиск упоминаний конкурентов для своего пиара
- Поиск возможностей для спонсорских постов
- Поиск тем Q+A, связанных с вашим контентом
- Проверка, как часто конкуренты публикуют новый контент
- Поиск сайтов со ссылками на конкурентов
Сначала полный список всех поисковых операторов Google и их функций.
- Как проводить поиск по интернет-странице
- Вопросы и ответы

Порой при просмотре какой-либо веб-страницы нужно отыскать определённое слово или фразу. Все популярные браузеры оснащены функцией, которая производит поиск в тексте и выделяет совпадения. Этот урок покажет Вам, как вызвать панель поиска и как ею пользоваться.
Как проводить поиск по интернет-странице
Следующая инструкция поможет быстро открыть поиск с помощью горячих клавиш в известных браузерах, среди которых Opera, Google Chrome, Internet Explorer, Mozilla Firefox.
И так, начнём.
С помощью клавиш клавиатуры
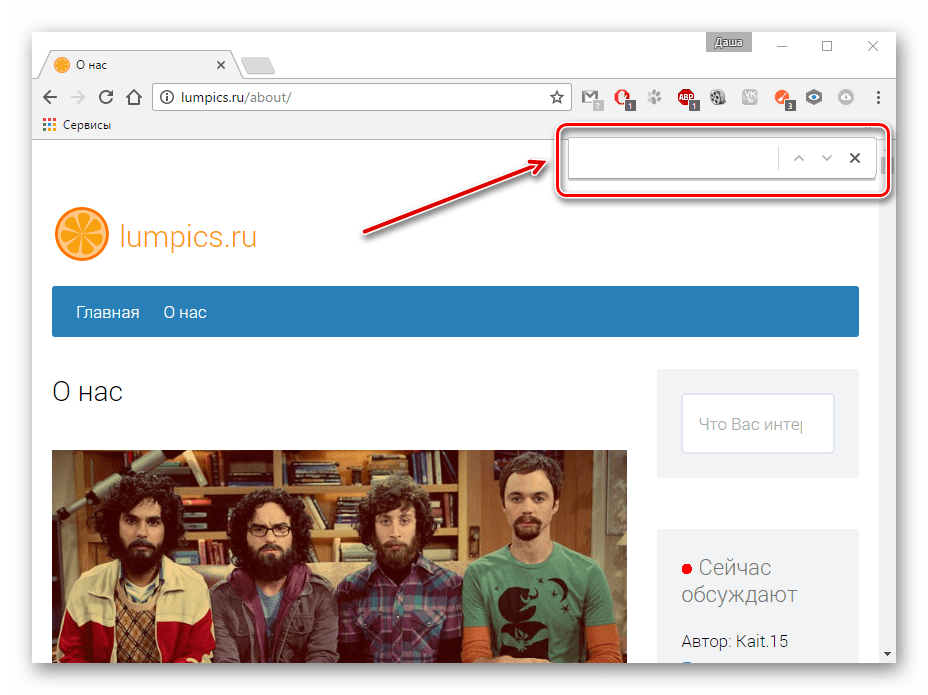
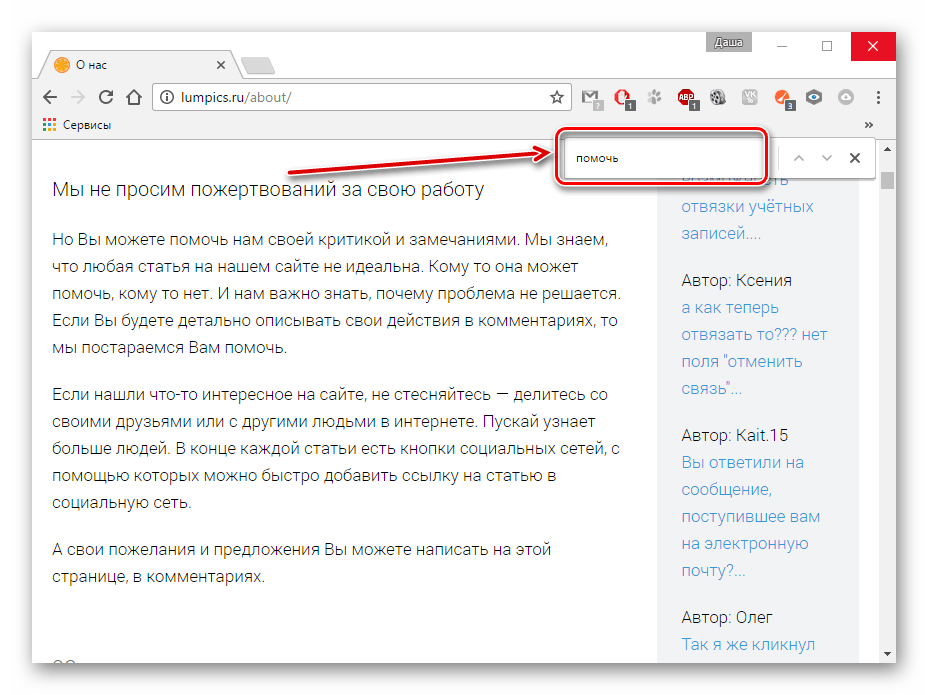
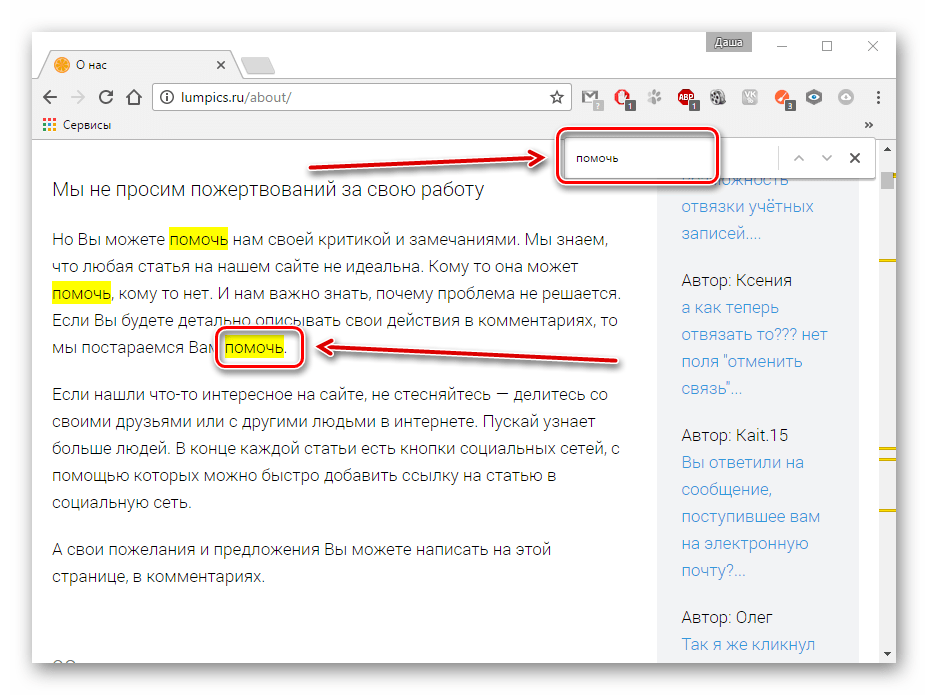
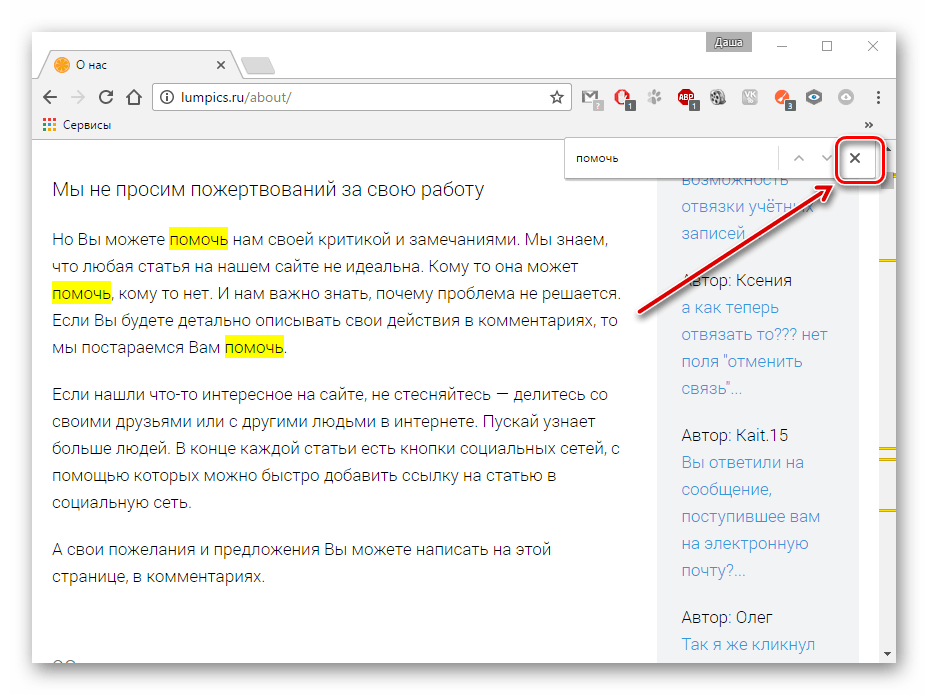
Вот так с помощью нескольких клавиш можно с лёгкостью найти на веб-странице интересующий текст, при этом не читая всю информацию со страницы.
Еще статьи по данной теме
- Ищем во ВКонтакте
- Вопросы и ответы
Любая социальная сеть, и ВК в том числе, представляет собой огромное хранилище разнообразной информации. ВКонтакте миллионы пользователей в разных странах со своими личными страницами, десятки миллионов фотографий, видеороликов, сообществ, пабликов, записей и репостов. Даже опытный юзер может легко «заблудиться» на просторах проекта. Как же правильно искать во ВКонтакте?
Ищем во ВКонтакте
В случае необходимости, применив разумный подход, каждый участник ВКонтакте может найти любую нужную информацию, которая является доступной для него в соответствии с правилами ресурса. Разработчики социальной сети любезно позаботились об этой возможности для своих юзеров. Давайте вместе попытаемся заняться поиском чего-либо в полной версии сайта и в мобильных приложениях для устройств на базе Android и iOS.
Вы также можете ознакомиться с другими подробными инструкциями по поиску ВКонтакте, размещёнными на нашем сайте, перейдя по ссылкам, указанным ниже.
Поиск в полной версии сайта
Сайт ВКонтакте отличается понятным и дружественным интерфейсом, который постоянно совершенствуется для удобства пользователей проекта. Действует целая система поиска с установками и фильтрами по рубрикам и разделам ресурса. Здесь не должно возникнуть серьёзных трудностей даже у начинающего пользователя.
Поиск в мобильных приложениях
Отыскать необходимые данные можно и приложениях для мобильных устройств на платформе Android и iOS. Естественно, что интерфейс здесь сильно отличается от полной версии сайта ВКонтакте. Но всё также просто и понятно для любого юзера.

Используя различные разделы и фильтры, можно отыскать фактически любую интересующую вас информацию, кроме закрытой по правилам ресурса.
Многие посетители сайтов не знают о поиске по странице по нажатию Ctrl+F и ищут необходимый фрагмент глазами, просто пролистывая текст. Этот способ становится проблематичным, если на странице текста больше, чем три-четыре экрана. Для таких посетителей я решил реализовать поиск по странице с использованием jQuery.
Пример подобного поиска есть на сайте Конституции РФ, но там он работает как-то странно.
Предупреждение
Я не профессиональный программист, просьба не пинать за кривой код и возможное изобретение велосипеда.
HTML-форма
Первым делом разместим на странице HTML-код формы поиска. Форма включает два элемента — поле для ввода текста и DIV для вывода результатов поиска.
CSS
Задаём два стиля: первый — для выделения фрагмента, второй — для ссылки на первый фрагмент.
Настройка поиска
var minlen = 3; // минимальная длина слова
var paddingtop = 30; // отступ сверху при прокрутке
var scrollspeed = 200; // время прокрутки
var keyint = 1000; // интервал между нажатиями клавиш
Подсветка фрагментов
Базовая функциональность — подсветка фрагментов в тексте. Делается это с помощью регулярных выражений.
Переход между фрагментами
Мало просто выделить фрагменты, гораздо удобнее организовать быстрый переход между ними. Под формой размещаем ссылку перехода на первый найденный фрагмент. Чтобы не занимать место стрелками, клик на каждый фрагмент ведет к следующему. Клик на последний фрагмент возвращает пользователя к форме поиска.
Задержка запуска поиска
Поиск в большом тексте и подсветка занимают несколько секунд, на которые страница зависает. При наборе длинного слова поиск производится после каждой введённой буквы.
Бонус
На больших страницах (примерно 60 кб текста) скрипт зависает на пару минут.
Спасибо за внимание, буду благодарен за замечания и идеи по улучшению работы скрипта.
Поиск возможностей для гостевой публикации

Но вы уже знали об этом методе, верно!? 😉
Примечание. Этот метод находит страницы с предложением написать статью. Такие страницы создают многие сайты, которые ищут авторов.
Так что применим более творческий подход. Во-первых: не ограничивайтесь одной фразой. Также можете использовать такие поисковые запросы:
- inurl:guest-post
- inurl:guest-contributor-guidelines
- и др.
Многие забывают один классный совет: можно искать всё сразу.

Можно даже искать эти фразу с учётом тематики.

Нужна конкретная страна? Просто добавьте оператор site:.tld .

Вот ещё один метод: если знаете конкретного блоггера в своей нише, попробуйте такой способ:
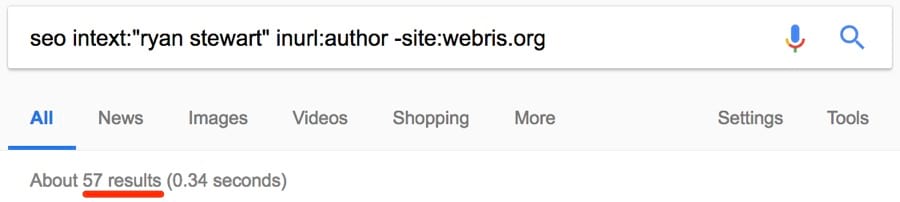
Так найдутся все сайты, где публиковался этот автор.
Примечание. Не забудьте исключить его сайт из выдачи, чтобы сохранить чистоту результатов!
Наконец, если вам интересно, принимает ли конкретный сайт статьи от сторонних авторов, попробуйте это:
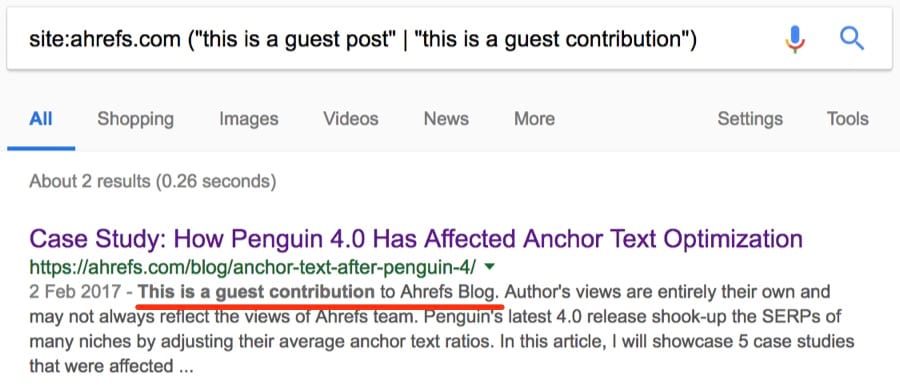
Примечание. В список можно добавить много других фраз.
Поиск сайтов со ссылками на конкурентов
На конкурентов ставят ссылки? Может быть, мы тоже можем их получить? Google прекратил поддержку оператора link в 2017 году, но он по-прежнему возвращает некоторые результаты.
Примечание. Обязательно исключайте сайт конкурента, чтобы отфильтровать внутренние ссылки.
Около 900 тыс. ссылок. Здесь тоже пригодится фильтр по дате. Например, за последний месяц на Moz поставили 18 тыс. новых ссылок.
Очень полезная информация. Но эти данные тоже могут быть неточными.
Поиск незащищённых страниц (не https)
HTTPS в наше время стал обязательным требованием, особенно для сайтов электронной коммерции. Но вы знали, что с помощью оператора site: можно найти незащищённые страницы? Проверим на примере asos.com.
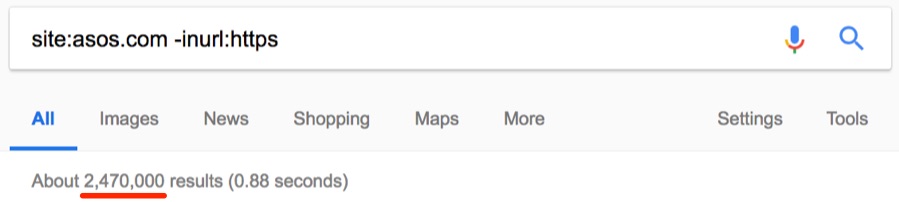
О боже, около 2,47 млн незащищённых страниц.
Похоже, что Asos вообще не используют SSL — невероятно для такого большого сайта.

Примечание. Клиентам Asos волноваться не стоит — страницы оформления заказа безопасны.
Но вот ещё одна вещь: Asos доступен в версиях https и http.
И мы узнали это с помощью простого оператора site:!
Примечание. Иногда страницы индексируются без https, но после перехода по ссылке происходит редирект на версию https.
Поиск готового решения
Первая мысль: кто-то уже точно такое писал, надо нагуглить и скопипастить. Так я и сделал. За час я нашел два неплохих скрипта, которые по сути работали одинаково, но были написаны по-разному. Выбрал тот, в коде которого лучше разобрался и вставил к себе на старничку.
Если кому интересно, код брал тут.
Поиск упоминаний конкурентов для своего пиара
Вот страница, на которой упоминается наш конкурент — Moz.

Найдено с помощью такого расширенного поиска:

Но почему нет упоминания блогов Ahrefs? 🙁
С помощью site: и intext: я вижу, что этот сайт раньше упоминал нас пару раз.
Но они не разместили никакой статьи с обзором наших инструментов, как в случае с Moz. Это даёт возможность. Свяжитесь с ними, пообщайтесь. Возможно, они напишут также про Ahrefs.
Вот ещё один классный запрос, который можно использовать для поиска отзывов о конкурентах:

Можете пообщаться с этими людьми, чтобы они повторно рассмотрели ваш товар/услугу.
Вот ещё один совет. Оператор daterange: устарел, но на странице поиска можно добавить фильтр для дат, чтобы найти последние упоминания конкурентов. Просто используйте этот встроенный фильтр.
Итак пишем скрипт с нуля
Как все у меня выглядит.
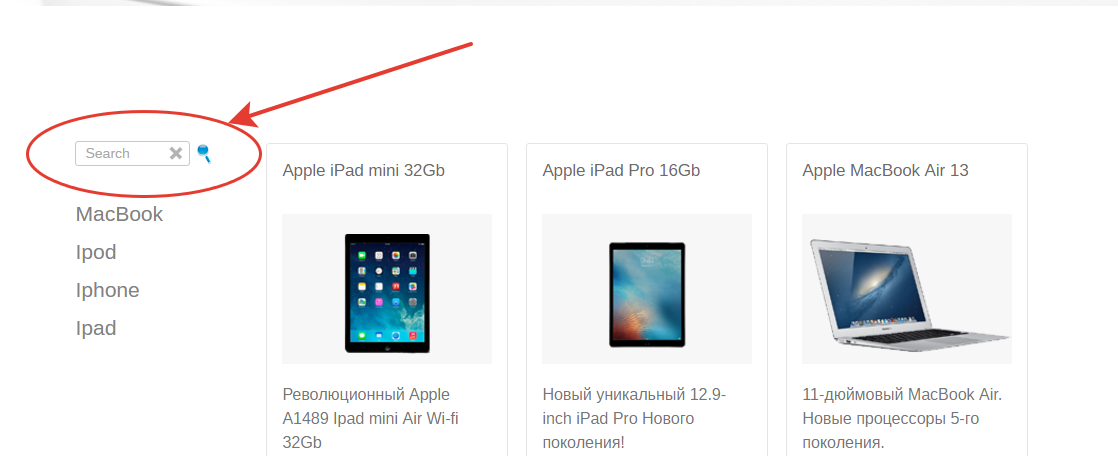
Сейчас нас интересует форма с поиском. Обвел ее красной линией.
Давайте немного разберемся. Я это реализовал следующим образом (пока чистый HTML). Форма с тремя тегами.
Первый — для ввода текста;
Второй — для для отмены поиска (снять выделение);
Третий — для поиска (выделить найденные результаты).
Итак, у нас есть поле для ввода и 2 кнопки. JavaScript буду писать в файле js.js. Предпложим, что его вы уже создали и подключили.
Первое, что сделаем: пропишем вызовы функции при нажатии на кнопку поиска и кнопку отмены. Выглядеть будет так:
Давайте немного поясню что тут и зачем нужно.
Полю с текстом даем id=«text-to-find» (по этому id будем обращатсья к элементу из js).
Кнопке отмены даем такие атрибуты: type=«button» onclick=«javascript: FindOnPage(‘text-to-find’,false); return false;»
— Тип: button
— При нажатии вызывается функция FindOnPage(‘text-to-find’,false); и передает id поля с текстом, false
Кнопке поиска даем такие атрибуты: type=«button» onclick=«javascript: FindOnPage(‘text-to-find’,true); return false;»
— Тип: submit (не кнопка потому, что тут можно юзать Enter после ввода в поле, а так можете и button использовать)
— При нажатии вызывается функция FindOnPage(‘text-to-find’,true); и передает id поля с текстом, true
Вы наверняка заметили еще 1 атрибут: true/false. Его будем использовать для определения, на какую именно кнопку нажали (отменить поиск или начать поиск). Если жмем на отмену, то передаем false. Если жмем на поиск, то передаем true.
Окей, двигаемся дальше. Переходим к JavaScript
Будем считать, что вы уже создали и подключили js файл к DOM.
Прежде, чем начнем писать код, давайте отвлечемся и сперва обсудим, как все должно работать. Т.е. по сути пропишем план действий. Итак, нам надо, чтоб при вводе текста в поле шел поиск по странице, но нельзя затрагивать теги и атрибуты. Т.е. только текстовые объекты. Как этого достичь — уверен есть много способов. Но сейчас будем использовать регулярные выражения.
Так мы будем находить нужные части кода, которые будем парсить и искать совпадения с текстом, который ввел пользователь. Затем будем добавлять стили найденным объектам и после этого заменять html — код на новый.
Приступим. Сперва переменные, которые нам понадобятся.
И сразу определим locale_HTML значение независимо от того, ищем мы что-то или нет. Это нужно, чтоб сразу сохранить оригинал страницы и иметь взможность обнулять стили.
var input,search,pr,result,result_arr, locale_HTML, result_store;
locale_HTML = document.body.innerHTML; // сохраняем в переменную весь body (Исходный)
Ок, теперь уже стоит создать функцию, которая вызывается у нас из DOM. Сразу прикинем, что внутри у нас должны быть 2 функции, каждая из которых срабатывает в зависимости от нажатой кнопки. Ведь мы либо проводим поиск, либо обнуляем его. И контроллируется это атрибутом true/false, как вы помните. Так же надо понимать, что при повторном поиске прежние стили должны обнуляться. Таким образом получим следующее:
Ок, часть логики реализована, двигаемся дальше. Необходимо проверять полученное слово на количество символов. Ведь зачем нам искать 1 букву/символ. В общем, я решил эту возможность ограничить 3+ символа.
Итак, сперва приниамем значение, которое ввел пользователь, и, в зависимости от его длины, выполняем либо основную функцию поиска, либо функцию вывода предупреждения и обнуления. Выглядеть будет так:
Сейчас поясню этот участок кода. Единственное, что могло стать не ясно — вот эта строка:
Тут все просто: метод innerHTML возвращает html код объекта. В данном случае мы просто заменяем текущий body на оригинальный, который мы сохранили при загрузке всей страницы.
Двигаемся дальше. Даем значения основным переменным.
Итак, на данном этапе у нас уже есть основные переменные и значения. Теперь надо придать нужным участкам кода стили с выделенным фоном. Т.е. проверка выбранного текста на регулярное выражение (по сути мы выбранный регулярным выражением текст снова парсим регулярным выражением). Для этого надо из введенного текста сделать регулярное выражение (сделали), а затем выполнить метод, переданный в виде такста. Тут нам поможет метод eval().
В общем, после того, как мы заменим текст и получим результат со стилями, надо текущий html заменить на полученный. Делаем.
По сути все готово, и скрипт уже работает. Но добавим еще пару деталей для красоты.
1) Обрежем пробелы у текста, который вводит пользователь. Вставляем этот код:
После этой строки:
input = document.getElementById(name).value; //получаем значение из поля в html
2) Сделаем проверку на совпадения (если совпадений не найдено — сообщим об этом). Этот код вставляем внутрь функции function FindOnPageGo() после переменных.
Теперь все. Конечно, можно добавить скролл к первому найденному результату, живой поиск ajax, да и вообще улучшать можно бесконечно. Сейчас это довольно примитивный поиск по сайту. Целью статьи было помочь новичкам, если возникет такой же вопрос как у меня. Ведь простого готового решения я не нашел.
P.S.: для корректной работы необходимо убрать переносы текста в html документе в тех местах, где есть обычный текст между тегами.
Это не принципиально, можно от этих переносов избаляться автоматически на сервисе, но может подскажете заодно, как это пофиксить, если поймете раньше меня.
Также, если кто писал подобное, но с живым поиском, поделитесь исходником, будет интересно разобрать.
Буду рад выслушать конструкнтиную критику, мнения, может, рекомендации.
На днях дописал немного код, сделал живой поиск по странице. Так, что вопрос снят. Код HTML не менялся. JS можете посмотреть тут.
Поиск ведется по тегам с классом «place_for_live_search». Так что для того, чтоб алгоритм парсил нужный контент, добавляем класс и готово.
Поиск профилей в социальных сетях
Хотите с кем-то связаться? Попробуйте найти контактную информацию таким способом:

Примечание. Имя человека обычно легко найти, а вот контактную информацию сложно.
Четыре лучших результата:
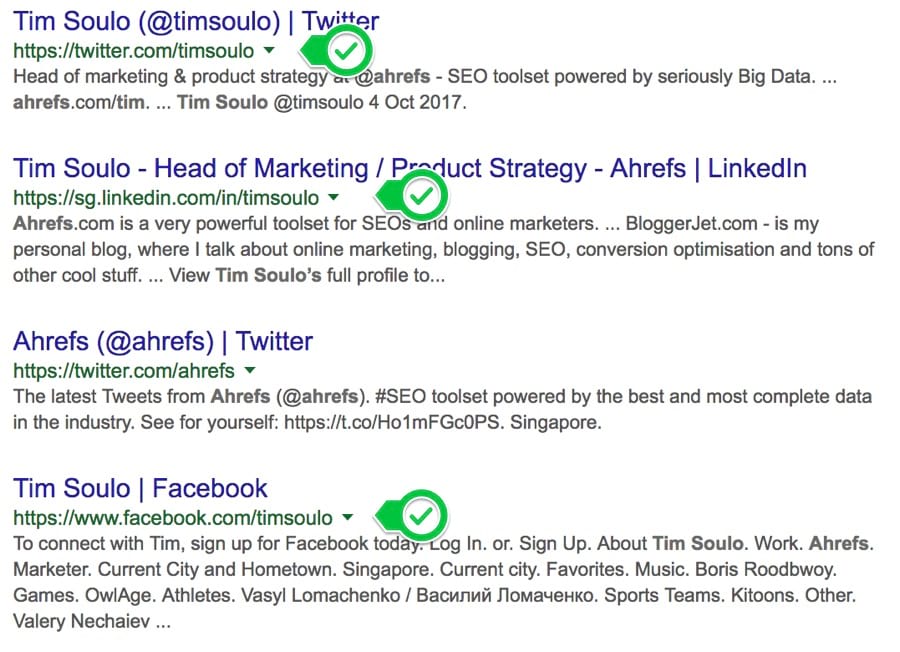
Затем можете связаться с человеком напрямую через социальные медиа. Или воспользуйтесь советами 4 и 6 из этой статьи для поиска адреса электронной почты.
Сломанные операторы
Операторы поиска Google, которые удалены и больше не работают.
Принудительный поиск по одному слову или фразе.
Пример: jobs +apple
Примечание. То же самое делается с помощью кавычек.
Включить синонимы. Не работает, потому что Google теперь включает синонимы по умолчанию. (Подсказка: для исключения синонимов используйте двойные кавычки).
Inpostauthor
Найти сообщения в блоге, написанные конкретным автором. Работало только в поиске по блогам.
Пример: inpostauthor:”steve jobs”
Примечание. Поиск Google по блогам закрыт в 2011 году.
Allinpostauthor
Аналогично предыдущему, но устраняет необходимость в кавычках (если вы хотите найти конкретного автора, включая фамилию).
Пример: allinpostauthor:steve jobs
Inposttitle
Найти сообщения в блоге с конкретными словами в названии. Больше не работает, так как этот оператор был уникальным для поиска по блогам.
Пример: inposttitle:apple iphone
Link
Поиск страниц, которые ссылаются на определённый домен или URL. Google убила этот оператор в 2017 году, но он по-прежнему возвращает некоторые результаты — вероятно, не особо точные (поддержка прекращена в 2017 году)
Info
Найти информацию о конкретной странице, включая время последнего кэширования, похожие страницы и т. д. (поддержка завершена в 2017 году). Примечание: идентичен оператору id:.
Пример: info:apple.com / id:apple.com
Daterange
Найти результаты по определённому диапазону дат. Почему-то использует юлианский формат даты.
Примечание. Официально не закрыт, но, похоже, не работает.
Phonebook
Найди чей-то номер телефона (поддержка прекращена в 2010 году).
Пример: phonebook:tim cook
Такие страницы собирают списки ресурсов по определённой теме.
Всё это — ссылки на сторонние ресурсы. По иронии, учитывая тему этой конкретной страницы — многие ссылки там не работают.
Так что если у вас есть крутой ресурс, можно найти соответствующие «ресурсные» страницы и подать заявку на добавление туда своей ссылки.
Вот один из способов найти их:

Но это может вернуть много мусора. Сужаем поиск:

Ещё больше сужаем:

Примечание об операторе #
Я знаю, о чем вы думаете: почему бы вместо этой длинной последовательности чисел не использовать оператор #..#. Хорошая мысль, попробуем:
Поиск дубликатов контента
Дубликаты — это плохо. Вот пара джинсов Abercrombie & Fitch на сайте Asos со стандартным описанием:

Стандартные описания сторонних брендов часто дублируются на других сайтах. Но интересно, сколько раз текст встречается на asos.com.
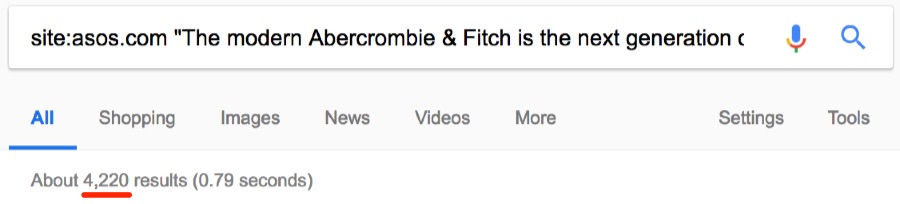
Примерно 4200 раз.
Теперь интересно, является ли текст уникальным для Asos. Проверим.

Нет, он не уникален. Есть 15 других сайтов с точно таким же текстом, то есть дублированным контентом. Иногда дубли присутствуют на страницах с похожими товарами. Например, аналогичные продукты или тот же товар в упаковках с разным количеством. Вот пример на сайте Asos:
Как видим, за исключением количества, страницы одинаковые. Но дубликаты встречаются не только на сайтах электронной коммерции. Если у вас есть блог, то люди могут красть и публиковать ваш контент без надлежащей ссылки. Посмотрим, может кто-то украл и опубликовал наш список советов по SEO.
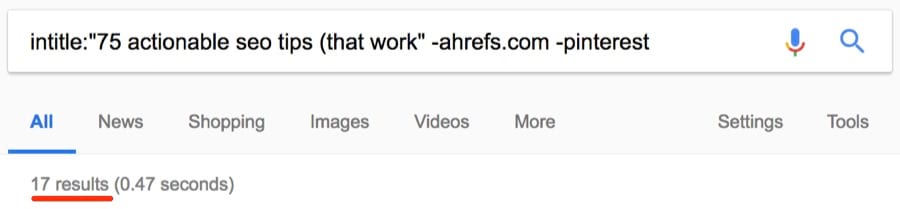
Около 17 результатов.
Большинство страниц, наверное, созданы в результате синдикации. Всё-таки стоит проверить, что они ссылаются на вас.
Кому вы можете предложить свою инфографику? Любым известным сайтам в своей нише?
Надо обратиться к сайтам, которые действительно захотят её опубликовать. Лучший способ — найти сайты, где уже публиковались такие материалы:

Примечание. Есть смысл поискать в пределах диапазона недавних дат, например, за последние три месяца. Если сайт публиковал инфографику два года назад, это не означает, что они таким занимаются до сих пор. Но если сайт публиковал её в последние несколько месяцев, то есть вероятность, что примет и вашу. Поскольку оператор daterange: больше не работает, придётся указать диапазон дат во встроенном фильтре поиска Google.
Но опять же, придётся отфильтровать мусор.
Вот быстрый трюк:
- использовать вышеуказанный запрос для поиска качественной инфографики по заданной теме;
- найти, где она размещалась.

Нашлось два результата за последние три месяца. И более 450 результатов за всё время. Проведите такой поиск для нескольких конкретных иллюстраций — и получите хороший список.

Получаем около 49 результатов, все похожие.
Примечание. В приведённом примере мы ищем сайты, похожие именно на блог Ahrefs, а не на весь сайт Ahrefs.
Вот один из результатов: yoast.com/seo-blog.
Я хорошо знаю Yoast, поэтому уверен, что это подходящий сайт для наших целей. Но предположим, что я ничего не знаю об этом сайте, Как проверить, что он подходит? Вот как:
- запустить site:domain.com найдите и записать количество результатов;
- делим второе число на первое: если оно выше 0,5, это подходящий вариант; если выше 0.75, то это просто супер.
Попробуем на примере yoast.com. Вот количество результатов для простого поиска:
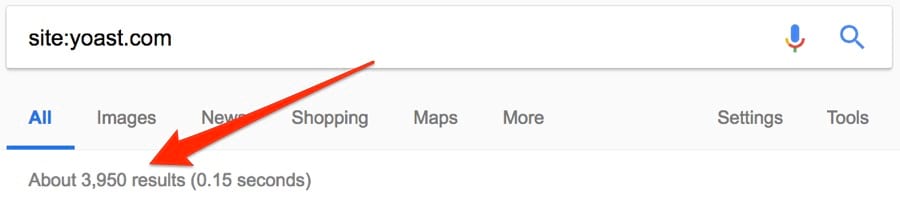

Итак, 3950 / 3330 = ~0,84. Отличный результат.
Теперь проверим на сайтах, которые точно нам не подходят.
Количество результатов для поиска site:greatist.com: ~18,000
Количество результатов для поиска site:greatist.com SEO: ~7
(18000 / 7 = ~0,0004 = совершенно нерелевантный сайт)
15 вариантов использования операторов поиска Google
Теперь рассмотрим несколько способов эффективного применения этих операторов, в том числе в сочетании друг с другом. Не стесняйтесь отклоняться от приведённых примеров, можете найти что-то новое.
Проверка, как часто конкуренты публикуют новый контент
Большинство блогов находятся в подпапке или поддомене, например:
- ahrefs.com/blog
- blog.hubspot.com
- blog.kissmetrics.com
Это позволяет легко проверить, насколько регулярно конкуренты публикуют новый контент. Проверим на одном из наших конкурентов: SEMrush.
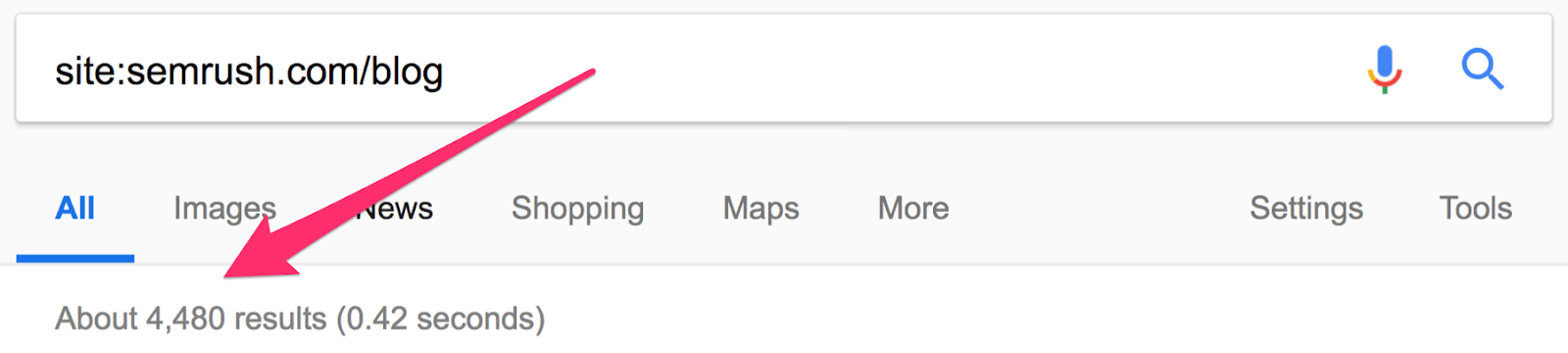
Похоже, у них уже около 4500 статей. Но это не совсем так. Сюда входят версии блога на разных языках, которые находятся на поддоменах.
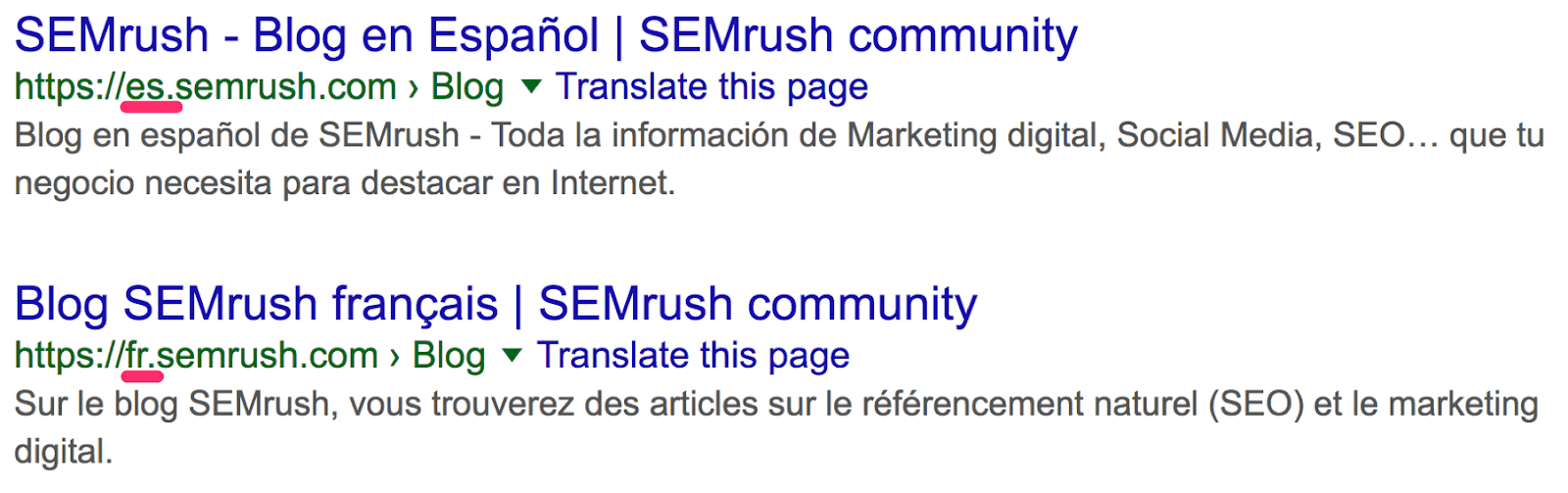
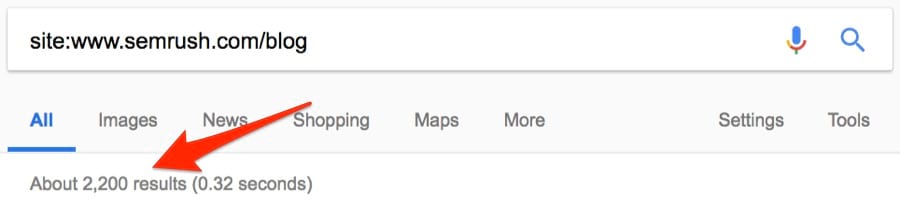
Это больше похоже на правду: около 2200 постов. Посмотрим, сколько опубликовано за последний месяц. Поскольку оператор daterange: больше не работает, используем встроенный фильтр Google.
Примечание. Можно указать любой диапазон дат. Просто выберите “Custom”.

Качество важнее количества, верно!?
Оператор site: в сочетании с поисковым запросом покажет, сколько статей конкурент опубликовал по определённой теме.
Поиск тем Q+A, связанных с вашим контентом
Форумы, а также сайты с вопросами и ответами отлично подходят для продвижения контента.
Примечание. Продвижение != спам. Не заходите на эти сайты только для того, чтобы добавить свои ссылки. Публикуйте ценную информацию, а по ходу дела иногда — уместные ссылки.
На ум приходит Quora, которая разрешает публиковать в своих ответах релевантные ссылки.

Это можно сделать на любом форуме или сайте с вопросами и ответами. Такой же поиск для Warrior Forum:

Я знаю, что там есть раздел о поисковой оптимизации. У каждой темы в этом разделе в URL указано .com/search‐engine‐optimization/. Так что я могу ещё больше уточнить запрос с помощью оператора inurl:.

Такие операторы даже лучше находят темы на форуме, чем встроенный поиск на сайте.
Поиск ошибок индексации
На большинстве сайтов есть страницы, которые Google проиндексирвоал некорректно. Возможно, какой-то страницы нет в индексе или наоборот, там присутствует что-то лишнее. Воспользуемся оператором site:, чтобы узнать количество проиндексированных страниц на моём сайте.

Примечание. Google здесь даёт примерное количество. Точную информацию см. в Google Search Console.
Но сколько из них являются статьями в блоге?
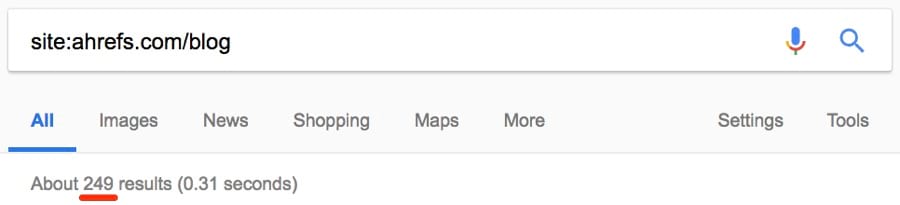
Я отлично знаю свой блог, поэтому уверен, что у меня статей реально меньше.

Кажется, проиндексировано несколько странных страниц.
(Это даже не реальная страница — она выдаёт 404)
Такие страницы следует удалить из индекса. Сузим поиск до поддоменов и посмотрим, что получится.
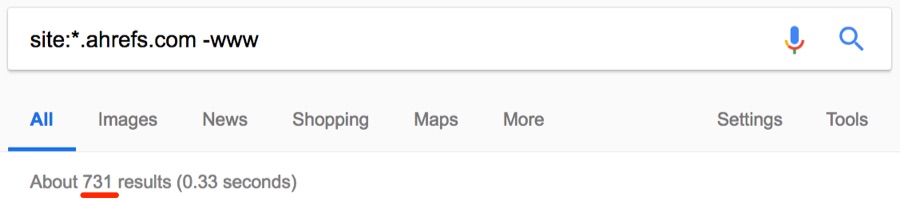
Примечание. Здесь мы используем подстановочный знак (*), чтобы найти все поддомены, принадлежащие домену, в сочетании с оператором исключения (-), чтобы исключить обычные результаты www.
Примерно 731 результат.

Есть несколько других способов выявить ошибки индексации:
- site:yourblog.com/category — найти страницы рубрик в блоге WordPress;
- site:yourblog.com inurl:tag — найти странице тегов в блоге WordPress.
Рабочие операторы
Принудительный поиск точного совпадения. Используйте его для уточнения неоднозначных результатов поиска или исключения синонимов при поиске отдельных слов.
Пример: “steve jobs”
Поиск по X и Y. Вернёт только результаты, связанные как с X, так и с Y. Примечание: в реальности не имеет значения для обычного поиска, потому что Google по умолчанию вставляет AND. Но очень полезен в сочетании с другими операторами.
Пример: jobs AND gates
Исключение термина или фразы. В нашем примере все страницы будут упоминать Джобса, но не с Apple (компанией).
Пример: jobs -apple
Действует как подстановочный знак для произвольного слова или фразы.
Пример: steve * apple
( )
Группировка нескольких терминов или операторов, чтобы контролировать выдачу.
Пример: (ipad OR iphone) apple
Поиск цен. Также работает для евро (€), но не для британского фунта (£).
Define
По сути, это встроенный в Google словарь. Показывает значение слова.
Cache
Возвращает последнюю кэшированную версию веб-страницы (при условии, что страница проиндексирована, конечно).
Filetype
Ограничивает результаты файлами определённого формата, например, pdf, docx, txt, ppt и т. д. Примечание: аналогично оператору “ext:”.
Пример: apple filetype:pdf / apple ext:pdf
Site
Результаты для определённого домена.
Related
Поиск сайтов, связанных с данным доменом.
Intitle
Аналогично “intitle”, но будут возвращает результаты, содержащие все указанные слова в теге title.
Пример: allintitle:apple iphone
Inurl
Аналогично “inurl”, но возвращает результаты со всеми указанными словами в URL.
Пример: allinurl:apple iphone
Intext
Аналогично “intext”, но возвращает результаты со всеми указанными словами на странице.
Пример: allintext:apple iphone
AROUND(X)
Пример: apple AROUND(4) iphone
Weather
Найти погоду для конкретного места. Отображается в погодном сниппете, но также возвращает результаты с других метеорологических сайтов.
Пример: weather:san francisco
Stocks
Биржевая информация (т. е., цена и т. д.) для любой акции по биржевому тикеру.
Map
Результаты поиска по картам.
Пример: map:silicon valley
Movie
Найти информацию о конкретном фильме. Также находит расписание сеансов, если фильм сейчас показывают недалеко от вас.
Пример: movie:steve jobs
Преобразует одну единицы измерения в другую. Работает с валютами, весами, температурой, расстояниями и т. д.
Пример: $329 in GBP
Source
Найти новостные результаты из определённого источника в Google News.
Пример: apple source:the_verge
Не совсем оператор поиска, но действует как подстановочный знак для автодополнения.
Пример: apple CEO _ jobs
Поиск возможностей для внутренних ссылок
Внутренние ссылки очень важны. Они помогают в навигации посетителей по вашему сайту, а также полезны для SEO (при разумном использовании). Но нужно убедиться, что вы добавляете внутренние ссылки только там, где это уместно. Допустим, вы только опубликовали большой список советов по SEO. Разве не здорово добавить внутреннюю ссылку на эту статью со всех страниц, где упоминаются советы по SEO?
Но не так легко найти соответствующие места для добавления этих ссылок, особенно на больших сайтах. Вот быстрый трюк:

Для тех, кто ещё не освоил операторы поиска, здесь мы делаем следующее:
- Ограничиваем поиск определённым сайтом.
- Исключаем страницу/публикацию, на которую требуется создать внутренние ссылки.
- Ищем определённое слово или фразу в тексте.
Вот одна из подходящих страниц, которую я нашёл таким запросом:

Поиск занял три секунды.
Поиск возможностей для спонсорских постов
Спонсорские посты — это платные статьи, продвигающие ваш бренд, продукт или услугу. Такой вариант не предназначен для размещения ссылок.
В руководстве Google явно запрещено:
Покупка или продажа ссылок, которые передают PageRank. Это включает в себя передачу денег на ссылки или сообщения, содержащие ссылки; передачу товаров или услуг в обмен на ссылки; отправку кому-то «бесплатного» продукта в обмен на то, что они напишут о нём и поставят ссылку.
Вот почему вы всегда должны следить за ссылками в спонсорских статьях.
Но истинная ценность этих статей всё равно не сводится к ссылкам. Это пиар, то есть демонстрация свого бренда перед нужными людьми. Вот один из способов найти возможности для спонсорских публикаций с помощью операторов поиска Google:
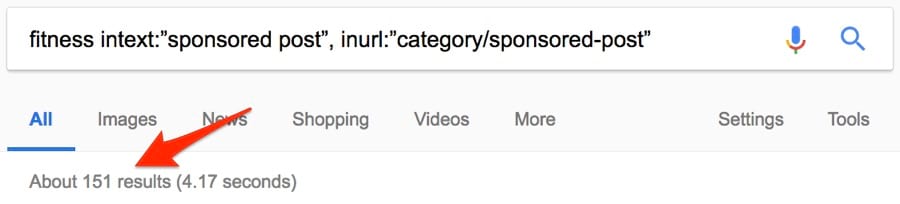
Примерно 151 результат. Неплохо.
Несколько других комбинаций операторов:
Примечание. Приведённые примеры — именно примеры. Почти наверняка эти сообщения можно найти по другим фразам. Не бойтесь проверять различные идеи.
Выполняем поиск без регистрации ВК
Идеальным вариантом решения вопроса ограничений поиска является регистрация нового аккаунта. Исходит это от того, что даже если вы сможете преодолеть ограничения, руководствуясь предлагаемыми способами, то у пользователей могут быть выставлены особые настройки приватности, скрывающие страницу.
Об упомянутых аспектах приватности вы можете узнать из специальной статьи.
Страница поиска
Этот способ является наиболее удобным и позволяет вам произвести полноценный поиск людей, сохраняя при этом возможность выбора критериев. Единственное ограничение в данном случае заключается в полном исключении из выдачи результатов тех аккаунтов, которые были скрыты пользователями через настройки приватности.
Перейти на страницу поиска людей ВК
Вдобавок к этому методу стоит отметить аналогичный способ поиска сообществ, отличающегося URL-адресом страницы и наименьшим количеством дополнительных параметров. Более подробно об этом, а также о поиске сообществ в целом, вы можете узнать из соответствующей статьи.
Перейти на страницу поиска сообществ ВК
Каталог пользователей
Администрация VK предоставляет совершенно любому пользователю сети интернет доступ к базе данных остальных пользователей. Благодаря данной методике вы можете без проблем узнать идентификатор страницы и имя хозяина аккаунта.
При этом способ имеет один весомый недостаток, заключающийся в том, что вам для поиска пользователей придется вручную искать человека без каких-либо вспомогательных средств, будь то возможность ввода имени или любых других данных.
Перейти на страницу каталога пользователей ВК
Единственный метод упрощения этого процесса заключается в вашей частичной осведомленности об идентификаторе разыскиваемой страницы.
В качестве заключения к данному способу важно добавить то, что в общем каталоге пользователей вам будут представлены все действующие страницы без исключений, независимо от выставленных настроек приватности. Более того, данные в каталоге обновляются в то же время, когда их вносит сам хозяин аккаунта.
Вам следует понимать, что даже имея доступ к переходу на страницу, основная информация или записи со стены вам не откроются. Единственное, что вы можете получить – это точное имя страницы и уникальный идентификатор.
Поиск через Google
Наименее комфортным и крайне неточным методом является розыск людей или сообществ путем использования поисковых систем. В целом, для этих целей подойдет практически любой существующий сервис, однако мы рассмотрим данную процедуру на примере Google.
Перейти на сайт Google
Вы можете использовать любые данные, будь то полное имя пользователя, никнейм или наименование сообщества.
Для простоты поиска рекомендуется следить за описанием каждой представленной страницы.
Обратите внимание, что точность и скорость обнаружения нужного профиля или сообщества, напрямую зависят не только от доступности, но и от популярности. Таким образом, чем большей популярностью обладает та или иная страница, тем выше она будет размещена среди результатов.
Кроме сказанного, вам следует ознакомиться с общими рекомендациями поиска людей на сайте ВКонтакте. В особенности это относится к возможности розыска людей по фото.
На этом все возможные решения вопроса касательно поиска без регистрации ВКонтакте, доступные на сегодняшний день, заканчиваются. Желаем вам удачи!
Поиск нежелательных файлов и страниц на своём сайте (о которых вы могли забыть)
Трудно уследить за всем на большом сайте, поэтому легко забыть о каких-то старых загруженных файлах: PDF, документы Word, презентации PowerPoint, текстовые файлы и т. д. Оператор filetype: поможет их найти.
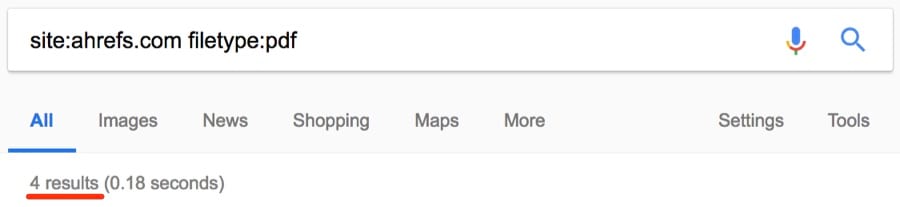
Примечание. Помните, что аналогичная функциональность у оператора ext:.
Вот одна находка:

Никогда раньше не видел этой статьи, а вы? Комбинируя несколько операторов, можно одновременно выводить результаты для разных типов файлов.

Примечание. Этот оператор также поддерживает .asp, .php, .html и др.
Важно удалить или деиндексировать их, чтобы они не попадались людям на глаза.
Частично рабочие операторы
Вот операторы, которые не всегда дают желательный результат:
Пример: wwdc video 2010..2014
Inanchor
Пример: inanchor:apple iphone
Allinanchor
Аналогично inanchor, но возвращает результаты, содержащие все указанные слова во входящих ссылках.
Пример: allinanchor:apple iphone
Blogurl
Поиск URL блога в определённом домене. Использовался в поиске Google по блогам, но кое-как работает и в обычном поиске.
Placename
Найти результаты из заданного места.
Пример: loc:”san francisco” apple
Примечание. Официально не закрыт, но результаты противоречивы.
Location
Найти результаты из заданного места в Google News.
Пример: location:”san francisco” apple
Заключение
Операторы расширенного поиска Google безумно мощные. Просто надо знать, как их использовать. Но я должен признать, что некоторые полезнее других, особенно в поисковой оптимизации. Я практически ежедневно использую site:, intitle:, intext: и inurl:, но очень редко прибегаю к помощи AROUND(X), allintitle: и многих других более мутных операторов.
Операторы поиска Google
Вы знали, что Google постоянно удаляет полезные операторы? Именно поэтому большинство существующих списков устарели и неточны. Для этой статьи я лично проверил каждый оператор, что смог найти.
Вот полный список всех рабочих, частично рабочих и сломанных операторов расширенного поиска Google по состоянию на 2018 год.