Что такое открытые данные?
Открытые данные (англ. Open Data) – концепция, отражающая идею о свободно-доступных данных. Они отличаются тем, что каждый заинтересованный пользователь может получить легкий и бесплатный доступ к таким данным, свободно использовать их и делиться с другими.
Ниже несколько, созданных специалистами Smart Analytics, примеров бесплатных ресурсов с открытыми данными в разных областях – экономике, демографии, образовании и других, где любой пользователь имеет возможность просматривать, анализировать, скачивать интересующую информацию и делиться ей с другими.
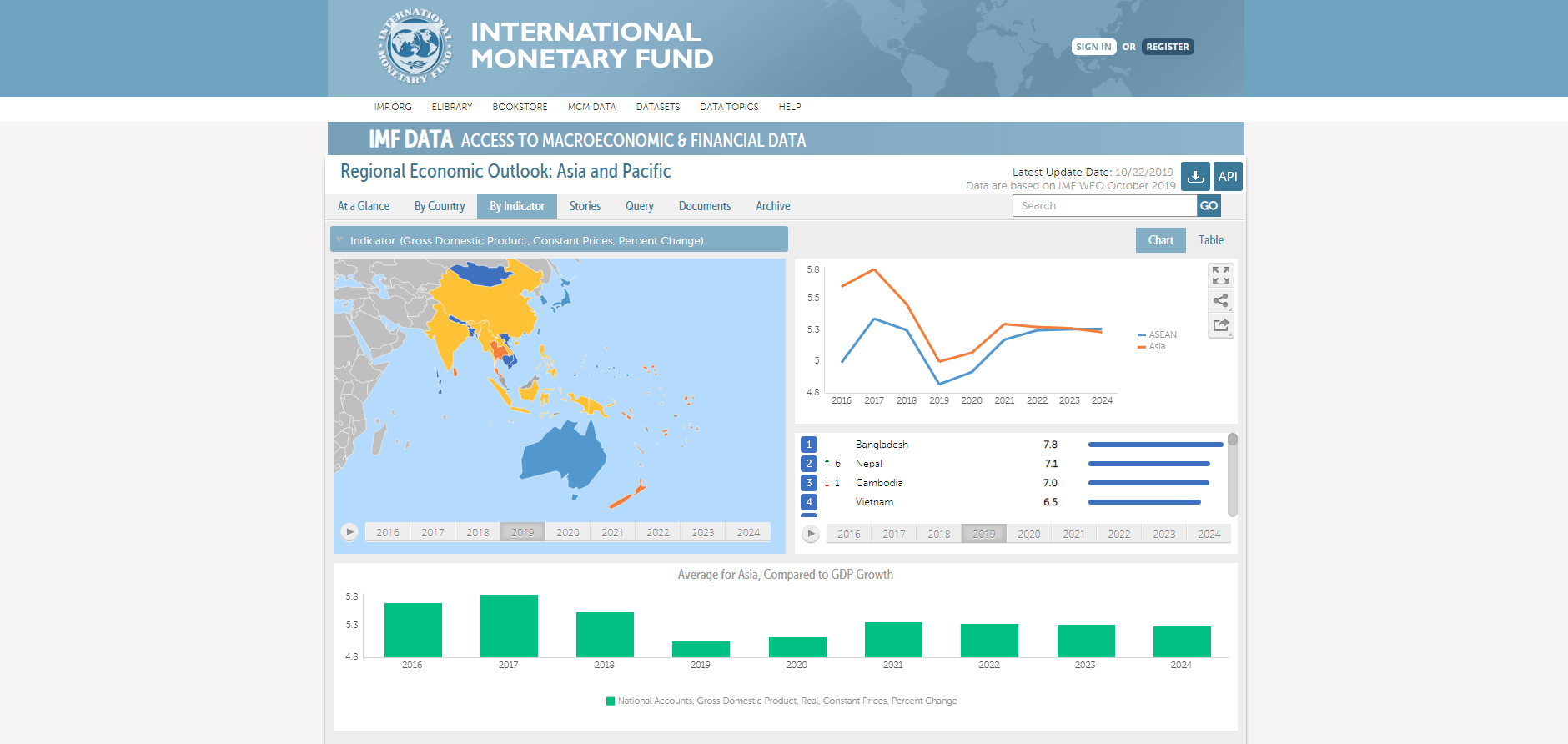
Портал данных Международного Валютного Фонда – это высоконагруженный веб-портал с данными по мировым макроэкономическим и финансовым показателям. Портал предоставляет доступ для 80 000+ уникальных пользователей в месяц по всему миру к 40+ статистическим датасетам, электронным публикациям и печатным сборникам.
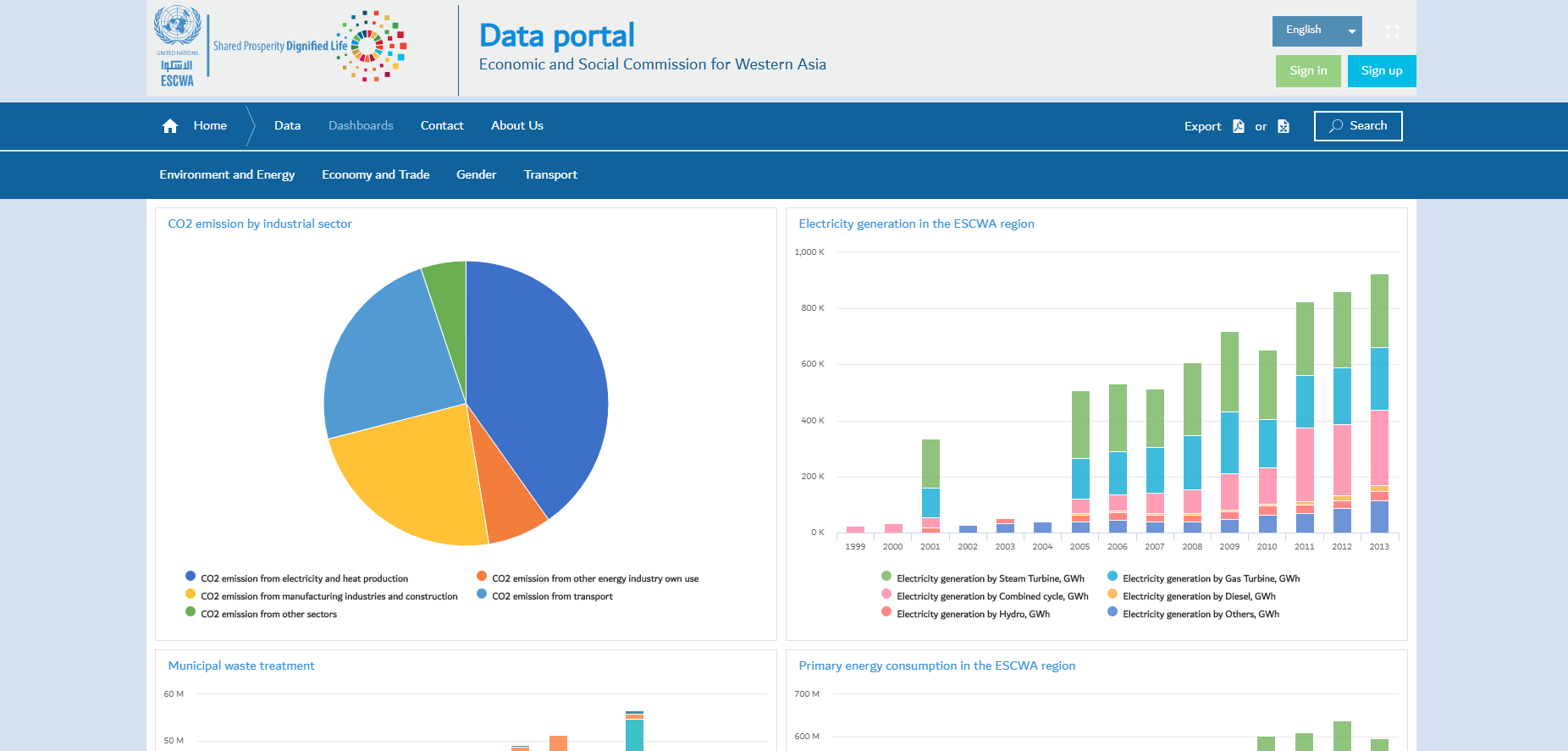
Портал данных ЭСКЗА ООН предоставляет доступ к статистическим данным по 18 странам Арабского региона, а также визуальные и аналитические возможности для формирования отчетов по данным региона, включая: статистику внешней торговли, промышленности, финансов и цен, численности населения и состояния здоровья, статистику в сфере образования и культуры.
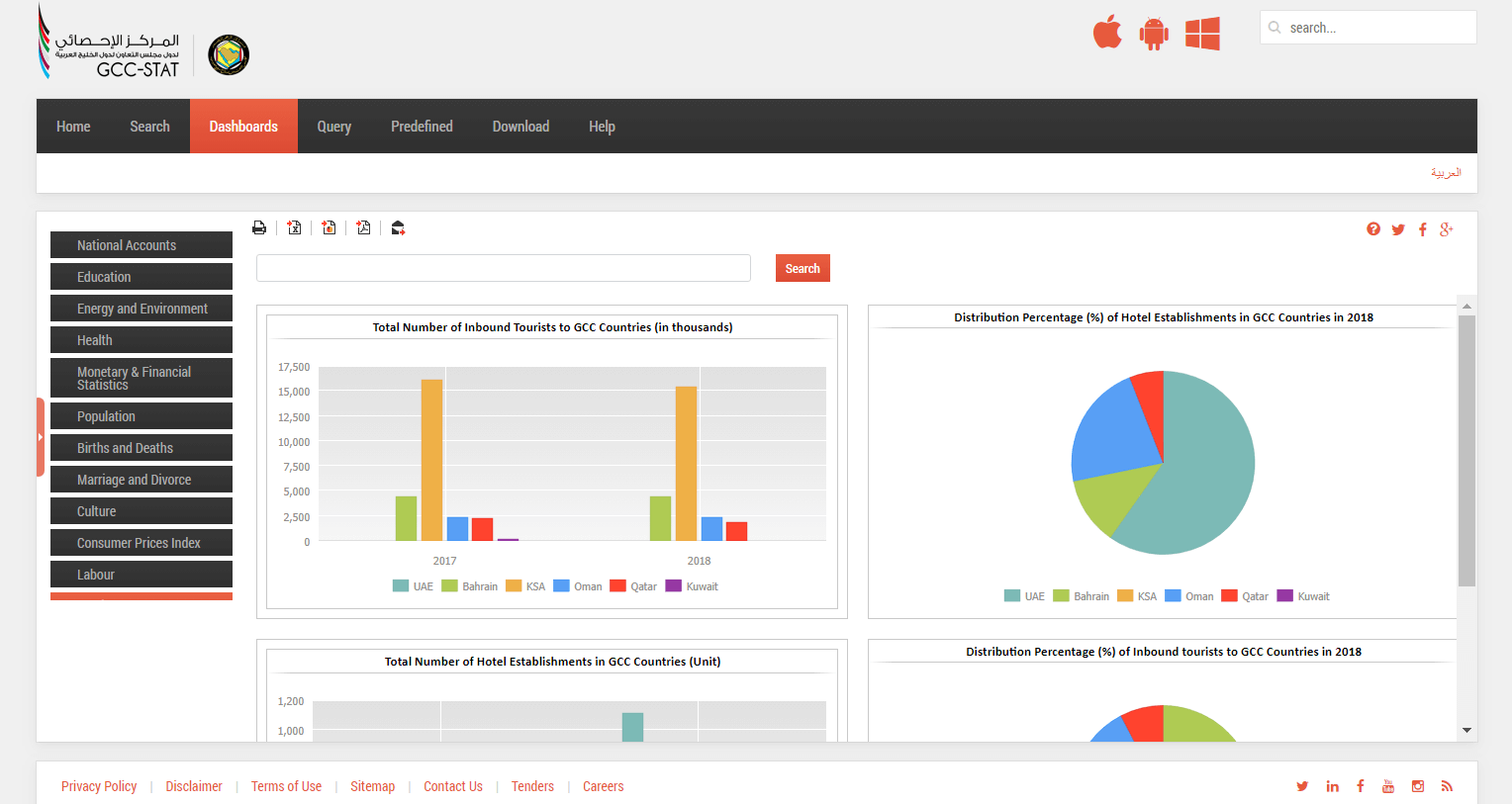
Портал данных GCC-Stat обеспечивает удобный и оперативный доступ к статистике государств Персидского залива. Он формирует единое информационное пространство для 6 стран региона и предоставляет посетителям возможности для анализа и визуализации данных, включая национальные счета, статистику по образованию, здравоохранению, населению и культуре.

Организация, которая не знает, какими данными располагает и какие могла бы получить, не может использовать их в качестве актива.

Даглас Лейни приводит высказывание директора по информационным технологиям крупной страховой компании: «Глупо, что у кого-то в компании есть опись нашей офисной мебели, но ни у кого нет описи того, какими данными мы располагаем».

Первый и самый очевидный способ начать разбираться с данными — это выделить и определить разные типы данных. Специалисты по управлению данными обычно классифицируют их по нескольким основаниям в зависимости от того, какие задачи им нужно решить. Так, по назначению и области применения принято выделять:
, описывающие структуру и характеристики данных;
— данные из справочников, международных, общероссийских и отраслевых классификаторов и т. п.;
— данные об объектах и бизнес-сущностях, представляющих ценность для организации (о клиентах, продуктах, работниках, технологиях и материалах и т. п.).
Очень часто вместо термина «основные данные» применяется термин «мастер-данные». Преимущества термина «основные данные» в том, что он определен и используется в комплексе национальных стандартов ГОСТ Р ИСО 8000 «Качество данных». См., в частности, ГОСТ Р ИСО 8000−2-2019 «Качество данных. Часть 2. Словарь».
Часто в отдельную категорию выделяют аналитические данные (см. рис. 12): они образуются из основных, справочных и транзакционных данных и используются в аналитической деятельности организации.
Рисунок 12 Взаимосвязи основных категорий данных в деятельности организации
На рис. 13 в качестве примера показаны роли каждой из категорий данных в информационном обеспечении процессов организации (в данном случае коммерческой). Отметим фундаментальную роль справочных и основных данных (мастер-данных) и важность их качества. Например, при наличии ошибок в данных о номере товара или типе клиента цена доставки будет определена некорректно (см. связи, обозначенные пунктиром), что может привести к серьезным финансовым последствиям.
Рисунок 13Роли отдельных категорий данных в информационном обеспечении процессов организации
По степени структурированности можно выделить:
- — данные, имеющие строго фиксированную структуру, определяемую формальной моделью данных (например, реляционной схемой);
- полуструктурированные (слабоструктурированные) данные — данные, не имеющие строго определенной структуры, но предполагающие наличие правил, позволяющих выделять отдельные семантические элементы при их интерпретации, прежде всего правил расстановки тегов и других маркеров, отмечающих и выделяющих элементы данных (например, файлы, созданные с использованием языка XML и его многочисленных производных, html-страницы и др.);
- — данные, произвольные по форме, не имеющие строго определенной структуры и не организованные по определенным правилам.
На рис. 14 приведены примеры форматов хранения и передачи данных для каждой из категорий.
Отдельно следует определить машинные данные и потоковые данные. К машинным данным относится информация, автоматически генерируемая компьютером, процессом, приложением или устройством без вмешательства человека (когда мы говорим об интернете вещей или о данных медицинского мониторинга, имеются в виду как раз машинные данные). Машинные данные становятся одним из основных источников информации, это в первую очередь относится к данным контроля и аудита (то есть к сведениям, фиксируемым в различных журналах регистрации).
Рисунок 14Форматы хранения и передачи данных с разной степенью структурированности
могут относиться почти к любой из перечисленных выше категорий, однако у них имеется одно дополнительное свойство. Данные поступают в систему при возникновении некоторых событий, а не загружаются в хранилище данных большими массивами. Примером потоковой обработки данных является сервис YouTube, проводящий анализ данных пользователей исходя не только из просмотренных ими полностью видеозаписей и трансляций, но и из материалов, которые они пропустили. Другим примером могут служить данные телеметрии, полученные с любого датчика или набора датчиков (например, системы «умный дом»).
При инвентаризации информационных активов целесообразно выделить группы в зависимости от данных. Приведем в качестве примера классификацию информационных ресурсов коммерческой организации, предложенную экспертами компании Gartner.
— это данные о клиентах, поставщиках, партнерах и сотрудниках, доступные в процессе онлайн-обработки транзакций и/или полученные из онлайн-базы данных аналитической обработки. Чаще всего их собирают с помощью датчиков и мониторинга процессов предприятий. Их источником могут быть, например, кассовые аппараты, подключенные к банковской системе, интеллектуальные счетчики, голосовая связь.
организации не собирают или не хранят специально; они формируются (попутно) в процессе ведения бизнеса или взаимодействия с сетевыми сервисами, после чего остаются в интернет-архивах. К ним относятся электронные письма, мультимедиа, системные журналы.
распространяются госорганами и коммерческими компаниями. Их ценность раскрывается в совокупности с другими источниками; они позволяют определить направления социально-экономического развития в отдельном городе, в стране или в группе стран.
Категория открытых данных тесно связана с категорией публичных данных. Термин «открытые данные» возник в американском научном сообществе в 1995 году как призыв к свободному обмену данными. Принципиальное отличие публичных данных состоит в том, что их использование регулируется законом — доступ к ним возможен, например, по специальному запросу. Смысл открытых данных в другом: они должны быть опубликованы еще до того, как кому-то понадобятся. Подробнее об открытости данных см. раздел 3.1.3.
— это сведения, представляющие коммерческий интерес, которые открыто размещаются в цифровой среде, в частности данные об активах, размещенные на открытых площадках.
Данные крупных социальных сетей активно используются как государственными, как и коммерческими структурами для получения ценной информации о рыночных и социальных тенденциях, о продуктах, услугах и сервисах, об общественном мнении и т. д.
Вернемся к общей картине управления данными. На рис. 15 показаны в общем виде отношения между категориями данных в организации.
Рисунок 15Соотношения между категориями данных
Данные из категорий, расположенных сверху, как правило, являются базовыми; они участвуют в формировании данных нижних категорий. Поэтому по мере движения вверх по списку категорий требования к качеству соответствующих данных возрастают. Также по мере продвижения вверх по списку категорий увеличивается продолжительность жизненного цикла данных. При движении вниз по списку категорий увеличивается объем самих данных, а также частота их изменений.
Поскольку данным разных категорий соответствуют разные требования, присущи разные риски и отведены разные роли в организации, многие инструменты управления данными сфокусированы на проблемах конкретных категорий данных. Например, основные данные имеют иное назначение и области применения, нежели транзакционные данные; соответственно, требования к управлению данными двух этих категорий будут отличаться.
В век диджитализации объём цифровых данных растёт такими темпами, что Big Data стала отдельной сферой внутри IT, и для работы с ней возникло несколько новых профессий.
Сегодня мы поговорим про дата-журналистов, которые создают истории на основе больших данных. Разберёмся, чем именно занимаются, какими навыками обладают и сколько зарабатывают такие специалисты.
Благодарим Бориса Ги, дата-журналиста и выпускника Нетологии, за помощь в подготовке материала.
Дата-журналистика, или журналистика данных, в России начала развиваться в конце 2000-х. Она возникла на стыке трёх областей: журналистики, аналитики данных и области создания визуального контента.
Дата-журналист — специалист, который ищет, обрабатывает и визуализирует данные, чтобы представить их в виде интересной и понятной читателю истории. Выглядит это так:

Это инфографика из исследования эпидемии ВИЧ в России от «Если быть точным». Чтобы рассказать о мерах борьбы государства с ВИЧ, дата-журналист опирался на соответствующий приказ Правительства и данные Роспотребнадзора, а также провёл собственные расчёты
Дата-журналист выбирает общественно важную тему, ищет по ней количественные данные, чтобы выявить закономерности, оценить масштабы явления и на основе этого прийти к выводам, которые могут помочь читателям разобраться в проблеме. Или, наоборот, автор идёт от данных — работает с каким-то массивом и находит что-то интересное, из чего можно сделать материал. В обоих случаях получается дата-история — с интересными фактами и инфографикой для наглядности.
С лучшими работами дата-журналистов со всего мира можно ознакомиться на сайтах известных журналистских премий: Data Journalism Awards и Sigma Awards.
Как и в классической журналистике, в дата-журналистике появляется идея или тема для создания материала. Но главным источником информации здесь выступают не интервью, очерки с мест событий или пресс-релизы, а данные. Именно они помогают проверить выдвинутые гипотезы, с их поиска и начинается работа над материалом.

В основе дата-истории лежит идея, которая проверяется данными
Для начала нужно определиться, где и какие данные брать для анализа. Информация должна быть актуальной и полной, поэтому лучше проверить сразу несколько источников.
Дата-журналисты обращаются к статистике с официальных сайтов государственных органов, справочной информации, опубликованным отчётам государственных и частных компаний о работе за определённый период и даже к информации из профилей пользователей соцсетей.

Если автор идёт от проблемы, поиск данных ведётся от общего к частному. Обычно алгоритм такой:
1. Сначала ищем данные Росстата и Единой межведомственной информационно-статистической системы (ЕМИСС). Как правило, хотя бы общие данные по большинству тем здесь есть.
2. Смотрим на законы, стратегии развития и государственные программы. Узнаём, какие ведомства занимаются проблемой, если это не очевидно.
Кроме того, в приложениях к стратегиям всегда есть целевые показатели и их текущие значения. Иногда это единственный открытый источник.
3. Изучаем сайты нужных нам федеральных ведомств — Минздрава, Минкульта — и региональных. Далеко не все данные попадают в ЕМИСС, некоторые датасеты публикуются на ведомственных сайтах.
Ещё нужные данные содержатся в отчётах и публикациях ведомств.
4. Проверяем сайты отраслевых институтов, НКО, фондов, различных исследовательских проектов.
5. Если данные указаны в перечне постановлений об открытых данных и должны собираться в рамках какой-то госпрограммы, но их нигде нет, делаем запрос в соответствующее ведомство, закон это позволяет.
Запрос можно направить, даже если у ведомства нет обязанности публиковать данные, но в таких случаях шансов получить ответ значительно меньше.
Запросы можно делать и в НКО, и в коммерческие организации. Как правило, они коммуникабельные и хотя бы самыми общими данными делятся.
6. Для определённых задач можно анализировать бюджеты и госзакупки. Некоторые ведомства дают доступ исследователям по API. Хотя сейчас таких всё меньше.
Бывают специфические задачи, которые требуют работы с текстами судебных решений, анализа соцсетей, парсинга данных из общедоступных источников. Но это, скорее, относится к варианту, когда журналист сначала исследует данные и понимает, что на их основе можно собрать материал.
Например, чтобы выяснить, кто и зачем приходит на Красную площадь, дата-журналисты Strelka Mag проанализировали 200 тысяч фотографий, опубликованных во ВКонтакте с соответствующий геометкой.

Оказалось, что приезжие фотографируют Красную площадь почти в 3 раза чаще москвичей
А для подготовки материала о важности самоизоляции в пандемию дата-журналист Андрей Дорожный использовал:
- данные о возрасте населения и количестве мест в больницах с сайта Росстата;
- исследование смертности от Covid-19 с сайта Национальной комиссии здравоохранения Китая;
- статью о формах коронавируса из журнала National Science Review;
- математическую модель прогнозирования развития пандемии с сайта Венского технического университета.

График показывает, в каком возрасте риск заболеть или умереть от коронавируса выше
Данных вокруг нас очень много. Правда, большая часть из них не структурирована, и для сбора и предварительной обработки нужны определённые навыки.
Кроме сайтов госорганов, данные можно искать и в других источниках ↓
1. Негосударственные хабы данных: Хаб открытых данных «Информационной культуры» и каталог данных «Инфраструктуры научно-исследовательских данных» (ИНИД).
Первый плохо структурирован, большая часть данных — это те же госданные, но в машиночитаемом формате.
В каталоге ИНИД данные качественные, но самих датасетов очень немного.
2. НКО и фонды, которые собирают данные по социальным проблемам. Например, «Если быть точным» и «Такие дела» ведут свою статистику. Фонд «Вера» ведёт учёт учреждений паллиативной помощи — правда, их данные не машиночитаемы.
К сожалению, у большинства НКО не хватает опыта и ресурсов для качественной публикации данных.
3. Коммерческие компании: Циан, Domofond, 2ГИС, Яндекс Карты, где данные можно собрать, нарушая правила сервиса, легально купить или получить по запросу.
Одни компании дают бесплатный доступ исследователям, у других — свободное API, но с рядом ограничений.
4. Компании-реселлеры данных, такие как Dadata. У Dadata есть бесплатный тариф, который позволяет взять по API достаточно много данных. Но эти данные больше ориентированы на коммерческую аналитику, а не на журналистику.
5. Соцсети и сервисы: ВКонтакте, YouTube, Spotify. У многих есть официальные API. ВКонтакте позволяет собирать огромное количество информации с минимальными ограничениями.
7. Сообщества, которые собирают негосударственные и некоммерческие открытые данные: Wikidata, OpenStreetMap и другие.
Однако важно помнить, что коммерческие, некоммерческие и любительские датасеты имеют ряд недостатков:
1. Мы не всегда можем верифицировать такие данные, проверить качество и добросовестность сбора.
2. Альтернативные данные часто недолговечны и неожиданно исчезают. А иногда они собраны с нарушением лицензий и законов, и поэтому ссылаться на них не всегда удобно.
3. Такие данные дополняют, но не всегда могут заменить государственные.
Например, данным о разводах или статистике смертности и рождаемости вряд ли можно найти замену.
Можно взять данные о семейном статусе из ВКонтакте, данные запросов из Wordstat или Google Трендов, объявления о поиске адвоката по разводам и тому подобное. Но это лишь дополнит картину.
Готовя материал о недвижимости, мы можем посчитать динамику цен, но данных из Росреестра это не заменит.
Будь то сырые данные, собранные автоматически, или официальный отчёт с сайта Росреестра — информацию важно проверить на несоответствия и ошибки. Пропуски, дубли, неправдоподобные цифры и опечатки могут повлиять на правильность выводов, ради которых журналист искал эти данные.
Ошибки в отчётах — это частое явление. Поэтому любой датасет нужно проверять: смотреть на типы данных, корректность выгрузки разделителей, дробей и так далее.
Иногда это не ошибка выгрузки, а опечатка — тогда стоит поискать второй источник или восстановить данные логически.
Если данные собраны в разное время или берутся из сборников Росстата, они могут немного отличаться. Это не ошибки, а поправки и уточнения — в этом случае я всегда беру более поздний вариант.
После очистки данные нужно упорядочить и структурировать — в сервисах электронных таблиц это можно сделать с помощью специальных формул и функций.
Теперь информацию будет проще анализировать:
- сравнивать,
- выявлять закономерности,
- вычислять,
- формулировать выводы.
На основе данных дата-журналист делает выводы, которые подтверждают или опровергают его гипотезу, показывают тренды, контрасты и скрытые взаимосвязи, которые самому читателю было бы сложно заметить.
Теперь найденные инсайты нужно представить в виде истории — рассказать о них понятным языком и визуализировать данные с помощью схем, графиков и диаграмм.
Иногда дата-журналист работает в команде с дизайнером и может поручить создание картинок для статьи ему — нужен будет набросок и ТЗ. Но в любом случае визуальную часть дата-историй стараются делать понятной, качественной и красочной, чтобы легче воспринималась и запоминалась.
Сейчас есть тренд на максимально простые и понятные визуализации: обычные линейные графики, столбики или линейчатые диаграммы, даже карты, в основном плиточные. Они рассчитаны на быстрое, почти моментальное считывание.
Несколько лет назад были популярны скролителлинг, всплывающие подсказки, интерактив. Сейчас этого почти нет.
Скролителлинг — это сочетание скроллинга и сторителлинга, когда пользователь читает текст по мере прокрутки анимированной страницы
- Научитесь искать истории, скрытые в массивах данных
- Поймёте, как использовать инфографику, лонгриды или интерактивные тесты, чтобы представить читателям полученные инсайты
- Начнёте работать по специальности уже через 5 месяцев обучения
Дата-журналисты востребованы там, где создают контент на базе точных, проверенных фактов с количественным обоснованием. Кроме СМИ, дата-журналистикой занимаются даже Сбербанк, Тинькофф и «Точка» — проводят исследования на основе своих данных, рассчитанные не только на внутреннюю аудиторию.
Вот перечень обязанностей дата-журналиста из вакансии РБК:

Из вакансии РИА Новостей:

А это обязанности дата-журналиста из вакансии Тинькофф Даты:

Получается, чтобы получить работу, дата-журналист должен уметь:
1. Искать актуальные данные:
- знать, какие базы данных существуют и как получить к ним доступ;
- уметь формулировать запросы и собирать необходимую для анализа информацию (парсинг).
2. Идентифицировать, фильтровать и структурировать информацию в программах обработки данных, таких как MS Excel или Google Таблицы.
3. Анализировать данные:
- понимать процедуру агрегации данных;
- знать основы статистики и уметь рассчитывать показатели, необходимые для анализа.
4. Визуализировать данные:
- подбирать и создавать диаграммы, графики, схемы, инфографику и другие иллюстрации;
- владеть программами для создания такого контента, например, уметь работать в Tableau.
5. Понятно и интересно писать — увлечь и удержать внимание аудитории, донося историю простыми и доступными средствами.
6. Программировать — иногда работодатели указывают в вакансиях и этот навык в качестве дополнительного. Вот что, например, ждёт от соискателя исследовательский проект «Если быть точным»:

Часто для анализа данных используют Python — это популярный язык, который позволяет быстро решать многие задачи.
В работе дата-журналиста бывают моменты, когда одного Excel недостаточно: спарсить данные с сайта, обработать XML-файл, выгрузить данные по API, просто открыть файл, в котором больше миллиона строк.
В редких случаях могут понадобиться инструменты для работы с большими данными, методы машинного обучения или обработки естественного языка. Для журналистских задач Python вполне хватит.
Однако дата-журналист — это не классический аналитик и тем более не Data Scientist. Поэтому, если Python или другой язык программирования освоить сложно, можно обойтись и no-code инструментами.
Средняя зарплата журналиста-универсала по Москве — 70 тысяч рублей в месяц, по России — 53 тысячи. Дата-журналист — более узкий специалист с дополнительными навыками, которые ценятся несколько выше.
Пока большой разницы между зарплатой журналиста и дата-журналиста нет, 80–100 тысяч рублей — стандартный месячный оклад.
Внештатные статьи и проекты тоже редко стоят дороже обычной журналистики. Например, в Т—Ж ставка за материал — 5 или 10 тысяч.
Конкретную зарплату в вакансиях на должность дата-журналиста указывают редко, обычно пишут, что условия обсуждаются индивидуально. Зарплата будет зависеть от объёма и количества выполняемых задач, а также от набора навыков и умений кандидата.
Фонд «Нужна помощь», например, предлагает соискателю от 80 тысяч рублей в месяц, а ещё ДМС со стоматологией:

Основная задача дата-журналиста — искать интересные инсайты в данных и объяснять их читателям в понятных историях и инфографиках. Поэтому специалист должен, с одной стороны, уметь разбираться в данных, а с другой — хорошо писать, но и тот и другой навык можно развить. Умения программировать и рисовать, которые развить сложнее, здесь второстепенны.
Дата-журналистами обычно становятся журналисты, аналитики, контент-маркетологи, product- и project-менеджерам, PR-специалисты и медиаменеджеры. Но попробовать может любой, кто чувствует к этому склонность.
Обучиться профессии дата-журналиста можно в НИУ ВШЭ по двухгодичной магистерской программе «Журналистика данных», она первой появилась в России в 2016 году.
Многие выпускники этой программы работают сейчас в известных российских редакциях. В 2019 году бывшая студентка НИУ ВШЭ Дада Линделл стала первой в России обладательницей премии Data Journalism Awards за несколько расследований, в том числе об увеличении в России смертности от ВИЧ.
Объёмы данных постоянно растут, и работа с ними — современный тренд. Зарубежные и российские издания хотят публиковать материалы, основанные на анализе больших данных, в понятном для читателя формате, и нуждаются в специалистах, способных выполнять такую работу.
Поэтому наряду с классической журналистикой появилась и быстро развивается дата-журналистика. Чтобы стать дата-журналистом, нужно уметь искать и читать данные, хорошо писать и работать в программах визуализации.
Учиться дата-журналистике в России можно в магистратуре или на онлайн-курсах, в обоих случаях программу преподают практикующие специалисты.
Мнение автора и редакции может не совпадать. Хотите написать колонку для Нетологии? Читайте наши условия публикации. Чтобы быть в курсе всех новостей и читать новые статьи, присоединяйтесь к Телеграм-каналу Нетологии.
Подпишитесь на блог
Будем делиться с вами своими знаниями и открытиями. Никакого спама, только польза.

БДСМ с БД ПМО или как я работал с госданными
Росстат ежегодно публикует порядка 4 тысяч показателей государственной статистики. Они доступны всем без каких-либо ограничений по статусу, правам доступа и т.п. Но публикуя данные, Росстат прежде всего ориентируется на то, что пользователи будут работать с ними вручную (глазами и руками), хотя последние 20 лет, мягко говоря, это не совсем тренд.
Меня зовут Веденьков Максим, я работаю в ЦПУР (Центр перспективных управленческих решений), некоммерческой организации, которая проводит исследования на государственных данных с целью повышения информированности общества о происходящих в стране процессах. Также мы собираем, обогащаем и публикуем датасеты с государственными данными, как ранее опубликованными, так и теми, которые раньше не публиковались.
В этой статье хочу рассказать об одном из таких наборов данных. Большом, сложном, важном, но при этом доступном в крайне неудобном для исследователей формате — базе данных показателей муниципальных образований (БД ПМО).
Программисты часто хотят найти изящное решение, которое может быть сложным, трудозатратным, но универсальным. Однако с государственными данными такое не проходит. Красной нитью через всю статью пройдет не столько то, какие мы молодцы (хотя мы, конечно, молодцы), сколько то, что иногда нужно просто заморочиться, и даже пойти на некое соглашение с самим собой (когда ты вынужден делать не особо квалифицированную работу), чтобы достичь цели.
Но прежде чем начать говорить о БД ПМО, стоит рассказать, зачем вообще нужно дополнительно обрабатывать открытые данные.
Дело в том, что исследователи — не программисты, у них другой стек навыков и инструментов. Исследователи хотят получать исходные данные в удобном виде, чтобы не нужно было совершать никаких дополнительных действий и можно было сразу приступить к анализу и исследованиям.
Вот пример исследования от моих коллег — «От избрания к назначению. Оценка эффекта смены модели управления муниципалитетами в России». Контекст был такой: по всей России отменяют или уже отменили выборы мэров, но никто не мог сказать, к чему это приводит на практике. Это не могли оценить, потому что для такой оценки нужны данные о том, что было до и что было после отмены, в разрезе по муниципалитетам. И за долгий период, чтобы можно было проследить историю.
Вот какие показатели, в частности, использовались при оценке:
- Расходы и доходы местных бюджетов
- Возрастная структура населения
Пример таблицы с данными о доходах местного бюджета:

Вывод исследования: Отмена выборов повлияла негативно, муниципалитеты стали беднее. В тексте исследования аргументация. А выводы и аргументация — это основа для принятия решений.
В примере выше данные фактически находятся в форме т.н. панельных данных (Panel data). Что это значит?
- Измерения охватывают достаточный период времени
- Различные объекты можно сравнивать между собой
- Все нужные переменные собраны в одну таблицу
При этом данные, которые выкладывают госорганы, далеки от такого формата, и БД ПМО в этом смысле — анти-чемпион.
Что такое БД ПМО
БД ПМО — это база данных показателей муниципальных образований, которую ведёт Росстат. Муниципальные образования — это элементы административного деления страны. А вот примеры показателей, которые в них отслеживаются:
- Общая площадь расселенного аварийного жилищного фонда
- Расходы местного бюджета, фактически исполненные
- Число лечебно-профилактических организаций
- Посевные площади сельскохозяйственных культур
- Оценка численности населения на 1 января текущего года
БД ПМО — одно из крупнейших хранилищ информации о социально-экономическом состоянии страны. Такая информация полезна социологам, экономистам, политологам, журналистам и другим исследователям. А их исследования, в свою очередь, полезны для общества и государства. Кстати, показатели, использованные для оценки эффекта смены модели управления муниципалитетами, тоже можно найти в БД ПМО.
В чём заключалась задача
Собрать 85 региональных баз данных в одну. Потому что никакой «базы» БД ПМО как единого объекта данных не существует. В каждом регионе своя БД, почти не связанная с другими. Структурно они должны быть идентичны, но на практике это не так, ведь их заполняют вручную сотни людей.
А теперь представьте нашу задачу на абстрактном уровне. У вас есть базы данных из 85 регионов, все они об одном и том же, но имеют микроразличия. И вам нужно объединить все базы так, чтобы устранить эти микроразличия, и сделать это корректно. Отталкиваемся от этой точки и идем далее.
Как устроена БД ПМО
Мы решили не парсить данные, а обратиться к первоисточнику. Росстат пошёл нам навстречу и передал дампы баз данных, значения из которых сейчас позволяет выгрузить конструктор на сайте Росстата, но отдельными таблицами.
То есть на входе мы получили дампы баз данных по всем субъектам в формате .bak (MS SQL Server) и один Word-файл с документацией. В развернутом состоянии они занимали ~200ГБ и содержали порядка 200 млн строк наблюдений. В среднем 780 таблиц в каждой БД.
Всего мы получили 82 базы — меньше, чем субъектов (85), потому что четыре автономных округа (Ненецкий, Ханты-Мансийский, Чукотский, Ямало-Ненецкий) включены в БД своих «родительских» субъектов, два из которых находятся в Тюменской области. Т.е. данные по Ямало-Ненецкому и Ханты-Мансийскому АО хранятся в базе по Тюменской области.
Вот так выглядит одна база:
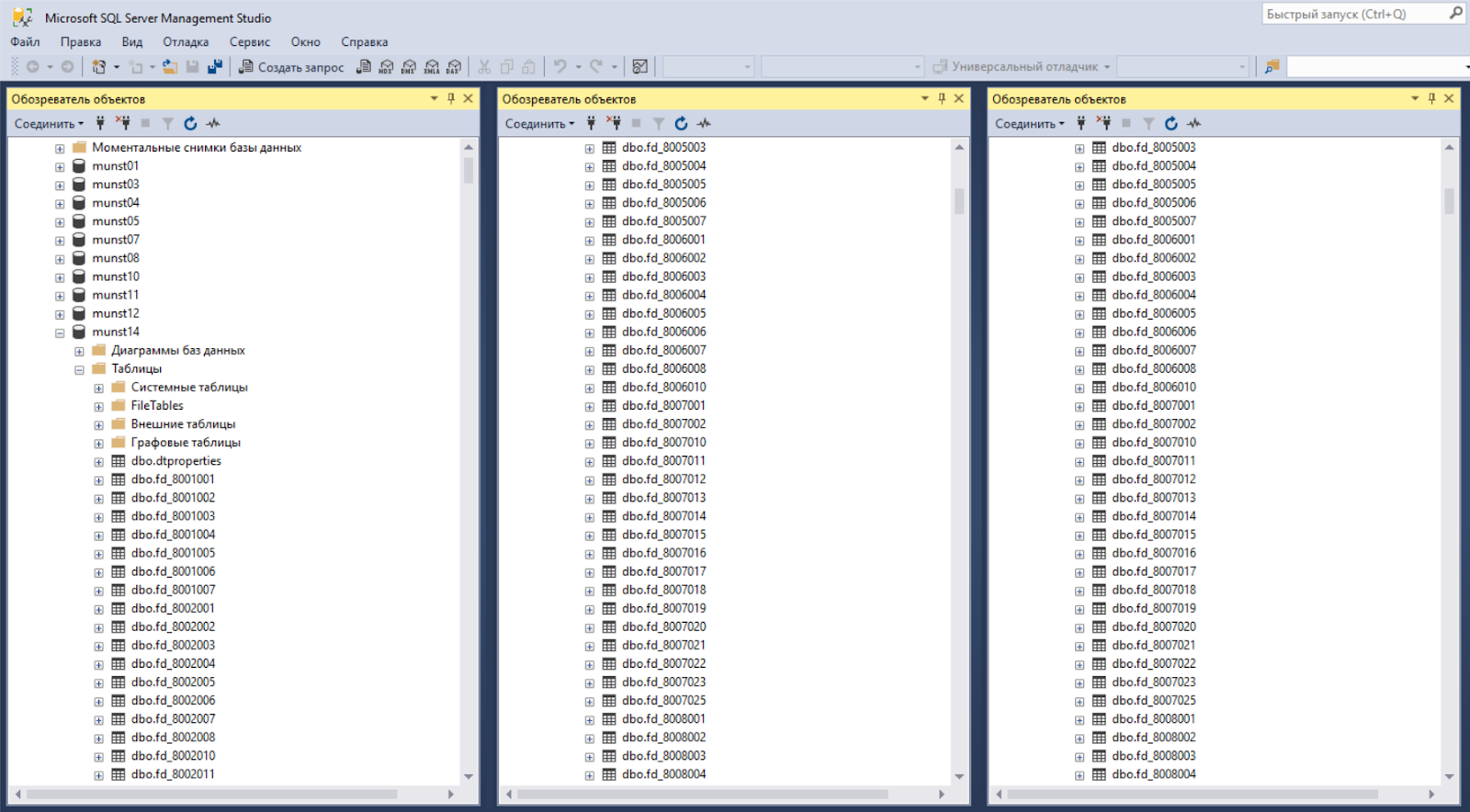
В каждой базе лежат таблицы двух типов: таблицы с данными и справочники. Одна таблица данных — это один показатель. Вот, например, данные по показателю «Число проживающих в аварийных жилых домах» (код 8008022):


В этой таблице не семь, а восемь атрибутов. Один дополнительный — это поле «stdohod», в которое записываются значения из группы категорий «Статьи доходов местного бюджета». А значение этого кода хранится в отдельной таблице-справочнике данной группы категорий. Вот он:
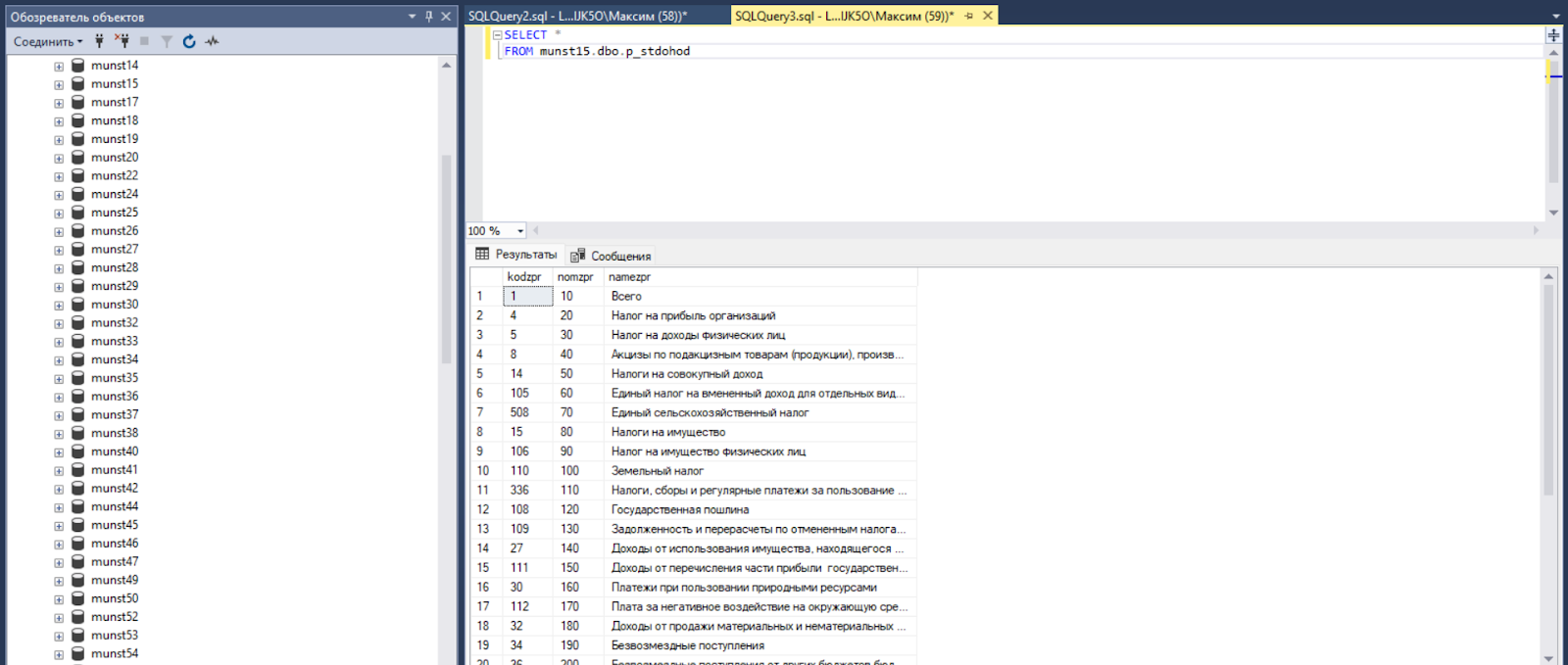
Если объединить таблицу данных со справочниками её атрибутов, то мы получаем полноценную panel data, т.е. заменяем коды категорий на сами эти категории.
В каждом регионе «своя версия» справочника. Т.е. один условный показатель — это 82 таблицы плюс 82 справочника для каждого атрибута в ней.

Про документацию
Вместе с базой мы получили внутреннюю документацию. В документации было ноль картинок, ER-диаграмм или каких-то других графических схем, зато было 26 страниц отборного казённого текста. Например, можете ли вы сразу понять, что содержат вот эти типы справочников: «Справочники вхождений значений признаков» и «Справочники разрезности значений признаков». Из названия смутно понятно, что есть некие признаки и разрезы. А если посмотреть в документацию, скажем, второго справочника, то там мы найдем такое: «Имя таблицы формируется путём присоединения приставки “p_” и окончания “_raz” к содержимому поля namesprav справочника признаков». Т.е. нет объяснения, что это, есть строго техническая информация.
И здесь первый вывод. Если вы сталкиваетесь с казённым языком в документации, то переписывайте её под себя, вводите новую терминологию, стандартизируйте названия, упрощайте формулировки, классифицируйте объекты данных, визуализируйте. Работайте с тем, что понятно вам, а не тем, кто написал это для вас.
Мы не стали делать этого сразу (это же долго), и это было огромной ошибкой. Любой контакт (совещание, статус, мозговой штурм) вне нашей маленькой команды наталкивался на стену непонимания от коллег, пока мы не ввели новую терминологию.
Каждая вложенная минута на переписывание документации окупится десятикратно, когда вам раз за разом не придётся отвечать на вопросы «Что это? В чем разница? Как они связаны друг с другом?». Она будет окупаться каждый раз, когда ваш мозг не будет тратить пару секунд, чтобы вспомнить, чем принципиально отличается «Справочник значений признаков» от «Справочника числовых значений признаков» и в каком из них лежит то, что вам нужно.
Сложность в том, что нет точки опоры, ни в чём
Допустим, вы получили такую задачу, какое первое нативное решение? Справочники приводим к эталону, данные очищаем от аномалий. Всё логично. Но этот путь не работает с БД ПМО.
Вспомним, что данные в БД ПМО — это статистические показатели. Вот, кажется, показатель, простая штука, например, «Число муниципальных спортивных сооружений». Но он может иметь от 4 до 7 групп категорий (атрибутов в таблице). Применяться в 10 или 85 регионах. Его могут заполнять раз в квартал, в год или в 10 лет. На 30 декабря текущего года или на 30 января года следующего за отчётным. Он может иметь одну из 27 единиц измерения. Натуральные показатели могут измеряться в шт и кг, денежные — в суммах от тысяч рублей до миллиардов. И конечно, все эти цифры разные: разные по годам, разные по регионам, разные для муниципальных образований в одном регионе. А ещё меняются границы регионов, меняется ОКТМО мун. образований, меняются названия.
Код ОКТМО — это восьмизначный код вида 14701000, который кодирует мун. образование. В данном примере 14 — это Белгородская область, 701 — город Белгород, 000 — ничего не значат. Если бы Белгород имел внутри себя другие муниципальные образования, то вместо 000 были цифры. Сам термин «ОКТМО» расшифровывается как «Общероссийский классификатор территорий муниципальных образований».
Базы разные между собой, потому что разные регионы. Взять какой-то из них за эталон невозможно. В Краснодарском крае выращивают в 60 тыс раз больше пшеницы, чем в Якутии. И Якутия из-за этого не становится аномалией. Другими словами, у вас нет диапазона валидных значений для показателей. А ещё показатель для одного региона может не применяться в другом. А ещё есть человеческий фактор: у каждого показателя есть ответственный по заполнению, и когда его нет на месте или его Windows 98 попросил обновления, нет и данных.
Показатели вводились не единовременно, а с годами. И истории этих изменений нет. Какие-то старые выводились, какие-то заменялись. Такие классификаторы как ОКВЭД и ОКОГУ (Классификатор видов экономической деятельности и органов государственной власти и управления) являются федеральными, а не росстатовскими. Следовательно, когда они изменялись, Росстат был вынужден проводить перекодировки параллельно во всех 82 базах. И конечно, это не обходилось без человеческих ошибок, которые, например проявляются в том, что используются одновременно два разных кода.
Другой пример. Показатели и категории также не являются статичными. С некой регулярностью они обновляются. Например, потому что вышел закон с обновлением кодов для федерального классификатора (ОКОГУ). И это делают тоже по-разному. В каком-то регионе просто меняют название категории под определённым годом, где-то вводят новый, дописывая что-то типа «с 2014 года» в новом и «до 2014 года» в старом. В результате мы получаем дубль (два разных наименования категории на один код).
Также, непросто формализовать и в цифрах посчитать такие метрики качества данных как полнота, непрерывность и целостность, чтобы опираться на них в дальнейшей работе. Вот, например, в таком-то регионе в таком-то сельском поселении данные были заполнены не по каждому селу, а по всему сельсовету. Формально они как бы есть, но уже агрегированные.
Эта особенность с агрегацией данных в БД ПМО является следствием её концепции, т.к. одно наблюдение — это значение показателя для одного ОКТМО. Проблема в том, что код ОКТМО — это сама по себе структурная единица, поэтому данные, заполненные для него, не являются атомарными (неделимыми). Поэтому, например, если вы посчитаете сумму по всем мун. образованиям Омской области, вы получите 43 млн человек населения:

Так происходит из-за того, что мунобразования, как матрёшка, вложены один в другой. А вложены они, потому что база не находится в третьей нормальной форме, т.к. поле ОКТМО содержит структурную информацию. А ОКТМО содержит структурную информацию, потому что оно является федеральным справочником и именно в привязке к ОКТМО сам Росстат получает данные. Вот такая матрёшка.
На практике эти проблемы проявляются в том, что у вас нет и не может быть единых паттернов поиска аномалий, не говоря уже об их устранении. А любая найденная аномалия с равной вероятностью может оказаться артефактом, или даже быть нормой для данного региона. И нет чётких критериев (кроме натуральных показателей, если, например, протяжённость трубопровода стала на 1 млн км длиннее за год) как определения аномалий, так и отличия аномалий от артефактов. План «находим аномалии, понимаем природу, находим универсальное решение» не работает на таком масштабе и вариативности, это слишком трудозатратно. Такое может занять месяцы работы команды людей.
В итоге мы пришли к следующему выводу: собираем базу, нормализуем справочники, но поиск и устранение аномалий оставляем исследователям. Это разумно по двум причинам:
- Во-первых, исследователи работают с гораздо меньшим количеством показателей по какой-то конкретной теме и погружены в неё гораздо больше, чем мы.
- Во-вторых, мы слишком рискуем, если будем чистить данные, убрать по-настоящему ценные артефакты, потому что они попали под паттерн аномалии.
Нормализация справочников
Со справочниками, в отличие от данных, было проще. Вот у вас есть 82 базы данных, и значит — 82 справочника. Например, kultur, «Сельскохозяйственные культуры». Напомню, справочник связан с данными вот так:

Эта таблица показателя «Посевные площади сельскохозяйственных культур» в Алтайском крае, в дополнительный атрибут (kultur) которого записан код 1010500. В справочнике этого атрибута код 1010500 кодирует категорию «Пшеница, яровая». Если в каждой базе под кодом 1010500 записана одна сущность, значит, проблем нет.
Это идеальный вариант. Но в реальности мы имеем несколько вариантов написания одной и той же сущности. Вот простейший пример, одна сущность, но разное написание:

В этом и есть проблема справочников. Они не нормализованы между базами, а эталона, к которому можно было бы их привести, тоже нет. Как их нормализовать и привести к эталону? Здесь работает нативное решение: создаём эталон из всех справочников по принципу «какая категория чаще применяется с кодом, та и есть эталон».
Здесь были свои сложности:
- Во-первых, каким способом считать метрику «разности» между категориями и какой трешхолд для этой метрики выбрать. Например, некая условная «категория 1» и «категория 2» отличаются только словами «с 2014 года», но дают разность в 86 (по Левенштейну). А «другая категория 1» и «другая категория 2» дают трешхолд в 80, но явно принципиально отличаются между собой.
- Во-вторых, если у вас пропорция 81/1, где в 81-й базе названия категорий совпадают, а в одной принципиально отличаются, то, где эталон, понятно. А если у вас пропорция 42/28? Уже не так очевидно.
- В-третьих, вот нашли мы такие проблемы (к слову, их было больше 2000), что с ними делать?
Первую задачу мы решили с помощью старого доброго Левенштейна. Вторую — с помощью здравого смысла. А третью — с помощью Росстата.
Кроме Левенштейна мы ещё пробовали посимвольную TF-IDF матрицу на разных алгоритмах. Технически, нужно было сравнить одно наименование категории с каждым другим из всех справочников и получить трешхолд. На практике трешхолд Левенштейна был наиболее понятным и точным из всех, поэтому оставлен был именно он. А валидацию результата мы проводили собственными глазами.
Природа пропорций вроде 42/28 оказалась во всех случаях одной и той же: сосуществование в справочниках как старых, так и новых кодов. В каких-то субъектах старые коды оставляли, в каких-то удаляли.
А как нам помог Росстат? Он взял на себя задачу по решению «сложных случаев». Мы собрали для них полный отчёт, в каких субъектах, в каких показателях и категориях есть проблемы, и отправили им. А они — региональным отделениям на детальную проверку.
План действий готов
Вот я сейчас описал вам всё это, и, кажется, понятно, в чём проблема. Как будто наш путь выглядел вот так:
На самом деле каждый из этих выводов, как и общий итог, не были очевидными с самого начала. 80% времени в работе с БД ПМО ушло на устранение неопределённостей и поиск путей решения, а не на само исполнение решения (коды, алгоритмы). Наш реальный путь выглядел примерно вот так:

Множество раз мы шли в каком-то направлении, понимали, что это движение не решает нашу задачу и откатывались назад. Мы искренне пытались найти некий универсальный путь, но его не было. В итоге мы пришли к компромиссу.
Вот как сейчас выглядит наш компромиссный пайплайн:
- Налаживаем коммуникацию. Переписываем документацию под себя. Упрощаем и сокращаем.
- Выбрасываем лишнее. Классифицируем таблицы по принципу «если есть ценность — оставляем, нет — удаляем». Например, справочник «Видов доступа пользователей» или пустая таблица «TestTable» ценности для нас не представляли.
- Конкретизируем конечную цель. Цель — панельные данные с заданным уровнем качества за ограниченный период времени.
- Конкретизируем критерии качества. Ставим на первое место полноту и достоверность.
- Вводим критерий трудозатрат. Мы понимаем, что можем больше, но это нерационально. Делаем то, что рационально.
- Выделяем проблемные области. Конкретные показатели или категории, которые вызывают сомнения в достоверности.
- Находим пути решения проблем. О них ниже.
Что конкретно мы понимаем под проблемной областью данных? Проблемная область — это X строк какого-то показателя, в котором мы сомневаемся, или X строк нескольких показателей, где применяется категория, в которой мы сомневаемся. Например, если в Алтайском крае под кодом 100 записана не категория «ячмень», как должно быть, а «отдано голосов за прежнего мэра», то проблемная область, это: показатель «Выборы мэра и ячменя», регион Алтайский край, все строки с кодом категории 100.
Выбрасываем лишнее — что именно? Служебные таблицы (список пользователей базы). Таблицы, информация из которых напрямую не связана с данными, например, вложенная группировка внутри группы категорий (есть и такое). Таблицы с некорректным названием, например, название показателя «fd_8001002_1» вместо «fd_8001002» (это копии таблицы данных на какой-то момент времени). Таблицы типа «TestTable». Старые версии справочников и т.д. Можно сказать, что мы вводим формальные критерии оценки ценности данных, критерии, оценка которых стоит «дешево» по времени.
Часть таблиц данных, возможно, и представляла интерес, но восстановление информации из них были признано нерациональным. Как по причине малого объема данных (< 1% от всех строк), так и потому, что часть неопределённостей ни мы, ни Росстат не смогли бы устранить.
Какие пути решения мы использовали? «Я принимаю реальность, а не сопротивляюсь ей». Или, другими словами, работали руки и глаза. Печень тоже.
По каждому показателю был собран детальный отчёт о полноте, периоде наблюдения и т.п. Исследователи из нашей команды и сотрудники Росстата проверяли показатели. Напомню, особенность показателей БД ПМО – в вариативности и достаточно длительном периоде наблюдения. Показатели «в моменте» почти бесполезны, они имеют ценность только при сравнении между регионами или внутри региона на длинном временном ряду (тренды). Поэтому те показатели из базы, что имели очень короткий срок наблюдения, прерывистость, малую полноту по регионам, исключались из массива данных. Из 608 показателей в итоговых данных осталось 355.
Из более чем 2 тыс проблемных случаев в справочниках все, кроме 187, нормализованы путем расчёта «похожести» по Левенштейну. Эти 187 «сложных» случаев отправлены в Росстат для проверки «на местах».
На момент написания этой статьи мы находимся в режиме ожидания этих изменений. В панельных данных, которые мы отдаем исследователям, данные с категориями «под сомнением» заменены на Nan.
В итоге получаем 79Гб панельных данных и новую БД
База — для нас, панельки — для исследователей, выводы — для всех. Панельки выглядят вот так:

Показатели сгруппированы по рубрикам (в примере выше рубрика «Спорт» ). Коды категорий заменены их значениями. В каждую таблицу добавлены единицы измерения и точная локация. Получилось удобно, не нужно что-то объединять. С этим могут работать даже те, кто хочет «просто в excel посмотреть» распределение (а такие есть и немало). Цифры: 25 рубрик, 355 показателей, 211 млн строк, 79Гб общий размер всех csv.
До выгрузки в панельный формат данные хранятся в нашей базе в PostgreSQL. Относительно оригинальной она почищена и пересобрана. Мы упростили структуру до трёх типов сущностей:
- Рубрики — это таблицы данных, содержащие несколько показателей, объединённых одной темой (например, спорт, население, здравоохранение и т.д.).
- Справочники групп категорий, которые содержат два поля — id категории и название категории. Через id категории мы можем смержить справочник с конкретным атрибутом в таблице.
- Мета-справочники — это справочники, связанные со всеми рубриками. В них входит: справочник показателей, их единиц измерения, кодировка рубрик, ОКТМО.
ER-диаграмма рубрики «Спорт»:

Каждый атрибут в рубрике связан со своим справочником (кроме поля со значением показателя и года). Это почти 3NF (код ОКТМО все ещё содержит структурную информацию), это легко в восприятии, это легко при выгрузке в панельные данные.
А что насчет выводов после этой работы?
Выводы есть. Вот процессы нашего пайплайна:
- Коммуникация в команде. Про это весь Scrum.
- Выбрасываем лишнее. Это история про MVP и минимальную достаточность.
- Конкретные цели и критерии. Это вообще про здравый смысл.
- Выделяем проблемные области, ищем решение, решаем. Это про MVP, здравый смысл и итеративный подход.
Ничего нового. Несмотря на нестандартность задачи, все так любимые в IT методологии работают и здесь. Скажем, я знаю их, я применяю их, этого достаточно? Не совсем, давай добавим смысл «я адаптирую их».
Как я писал выше, 80% времени в работе с БД ПМО ушло на устранение неопределённостей и поиск путей решения. Наверное, каждый из нас способен принять лучшее решение, если он обладает двумя вещами: знаниями и полнотой информации. А если полноты информации нет? И устранение неопределённостей не приближает тебя к цели? Наверное, стоит устранять неопределённость более системно?
В такой момент я вспоминаю цикл НОРД, состоящий из четырёх повторяющихся процессов: наблюдение, ориентация, решение, действие. Эту ментальную стратегию разработал стратег и полковник ВВС США Джон Бойд. Раз он полковник, значит, он придумал её не для покупки молока, а, скажем, чего-то типа победы в войне.
В этой стратегии есть два способа достижения целей: быстрее проходить петлю НОРД или повышать качество принимаемых решений за счёт удлинения процессов наблюдения и ориентации. И сейчас я бы сказал, что первый способ более выигрышный.
Мы очень долго «разбирались» в БД ПМО. Мы понимали больше, но это не приближало нас к законченному продукту. Прогресс пошёл тогда, когда мы стали отрезать лишнее, отрезать непонятное и делать какой-то ограниченный продукт на известных и понятных данных — там, где нам хватало знаний и понимания вопроса, чтобы создать понятную применимую ценность.
Да это же Agile, скажете вы? Да, точно. Адаптированный к задаче. Где адаптация заключается в том, что каждый трек начинается с устранения неопределённости в какой-то локальной области задачи (когда нет ТЗ, когда план на трек невозможно написать, не устранив эту неопределённость), постановки цели, и, наконец, решения.
Принципы открытых данных
Правительственные данные считаются открытыми, если соответствуют следующим восьми принципам:
- Первичность. Публикуются данные, собранные из первоисточника, с максимальным уровнем детализации, а не в агрегированных или измененных формах
- Полнота. Все публичные данные становятся доступными. Открытыми должны быть все государственные данные, за исключением данных, которые подпадают под ограничения доступа, определенные законом
- Актуальность. Данные публикуются так быстро, насколько это необходимо для сохранения их актуальности и ценности
- Доступность. Данные должны быть доступны широкому кругу пользователей для широкого круга задач
- Пригодность к машинной обработке. Данные должны быть представлены в электронном структурированном виде для последующей автоматизированной обработки
- Отсутствие дискриминации по доступу. Данные доступны для всех, без каких-либо требований к регистрации. К данным должен быть разрешен анонимный доступ
- Отсутствие проприетарных (являющихся частной собственностью авторов или правообладателей) форматов. Данные доступны в формате, над которым ни один субъект не имеет эксклюзивный контроль
- Лицензионная чистота. Данные не имеют авторских прав, товарных знаков или патентов
Идея, лежащая в основе данных принципов, заключается в том, что публичные данные – это общая собственность, которой можно делиться и которую можно использовать каждому.
Преимущества открытых данных для органов государственного управления
Открытые данные являются важным элементом открытого государственного управления и повышают эффективность государственной деятельности.
Доступ к информации и знаниям также влияет на состоянии экономики. Когда информация предоставляется бесплатно, компании и частные лица более активно пользуются этой информацией для создания добавленной стоимости товаров и услуг. Это увеличивает обороты частного сектора, доход государства в виде налогов, стимулирует экономику.
Также, порталы открытых используются для мониторинга целей ООН в области устойчивого развития (Sustainable Development Goals). Такие веб-порталы содержат информацию о прогрессе в достижении целей, помогают выявить цели и задачи с наиболее сложной ситуацией, отображают процент показателей с положительной динамикой и позволяют проводить сравнительный анализ эффективности стран в достижении целей устойчивого развития.
Наш Портал открытых данных позволяет визуализировать информацию в виде таблиц, диаграмм, графиков и текстов. В ЭСКЗА ООН еще никогда не было настолько удобного и интуитивно-понятного инструмента для распространения данных.
Порталы открытых данных от Smart Analytics позволяют оперативно создавать электронные публикации и отчеты в виде презентаций с текстом, диаграммами и картами с помощью встроенной CMS и распространять данные среди пользователей по всему миру.
Для пользователей открываются широкие возможности, которые позволяют:
- Анализировать данные, используя сквозной поиск и извлечение информации из датасетов, временных рядов, отчетов и публикаций
- Использовать мощные инструменты визуализации данных в виде таблиц, графиков, диаграмм и карт с возможностью создавать и настраивать собственные дашборды прямо в системе
- Выгружать данные через открытый API в различных форматах (XLS, XLSX, PDF, RTF, HTML, MHT, PPTX, JPG, PNG) для последующего анализа и использования данных
Зеркальные копии приложений обеспечивают поддержку непрерывной работы, чтобы сотни тысяч пользователей в любой момент времени имели доступ к порталу с любого устройства: ПК, мобильного телефона или планшета.
Посмотрите, как сотрудничество Smart Analytics с международными организациями помогло сделать открытые данные основой для реальных действий в разделе Истории успеха.