Геннадий Красников рассказал о предложениях РАН на заседании Совета по науке и образованию при Президенте РФ
Президент обозначил направления развития научно-технической сферы
Масштабы разрушений после землетрясения в Турции показали из космоса
Противодронные устройства защитили от беспилотников нефтяную компанию
Платиновый катализатор многократного использования удешевит производство силиконов и убережет природу от загрязнения
Щёлкает как орехи. Крокодил продемонстрировал силу своих челюстей
В Книге Откровения обнаружили сходство с табличками проклятий
Ученые разработали кремниевые детекторы для контроля характеристик нейтронных полей активной зоны ядерных реакторов
Десятилетие науки и технологий
Молодые российские ученые стали героями выставки «Наука в лицах» в ГУМе
В поисках «слабого места» у туберкулезной палочки учёные исследовали ферредоксины
Речь вовсе не о «Яндексе» или Bing. Есть поисковые сервисы, которые действительно лучше, чем лидеры рынка. Пусть и не во всём.
1. DuckDuckGo
Что это
DuckDuckGo — это довольно известная поисковая система с открытым исходным кодом. Серверы находятся в США. Кроме собственного робота, поисковик использует результаты других источников: Yahoo, Bing, «Википедии».
Чем лучше
DuckDuckGo позиционирует себя как поисковик, обеспечивающий максимальную приватность и конфиденциальность. Система не собирает никаких данных о пользователе, не хранит логи (нет истории поиска), использование файлов cookies максимально ограничено.
Зачем это вам
Все крупные поисковые системы стараются персонализировать поисковую выдачу на основе данных о человеке перед монитором. Этот феномен получил название «пузырь фильтров»: пользователь видит только те результаты, которые согласуются с его предпочтениями или которые система сочтёт таковыми.
DuckDuckGo формирует объективную картину, не зависящую от вашего прошлого поведения в Сети, и избавляет от тематической рекламы Google и «Яндекса», основанной на ваших запросах. При помощи DuckDuckGo легко искать информацию на других языках, тогда как Google и «Яндекс» по умолчанию отдают предпочтение русскоязычным сайтам, даже если запрос введён на иностранном.
2. You.com
Что это
Один из новых поисковиков, выдача которого формируется не по принципу «самый короткий релевантный ответ», а представляет собой всестороннюю выжимку данных из различных источников, включая соцсети, сообщества и форумы.
Чем лучше
У You.com современный интерфейс и приятный дизайн, которые обеспечивают наглядность информации и позволяют одним взглядом охватить полную картину. Результаты отображаются в виде блоков и разбиты на категории.
В зависимости от запроса поисковик даёт релевантные подсказки, пытаясь предугадать ваши мысли. А в выдачу попадают не только популярные сайты, но и малоизвестные проекты при условии, что у них есть правильный ответ на вопрос.
Зачем это вам
You.com удобнее многих других поисковиков и значительно экономит время. По сути, сервис гуглит за вас и в один клик предоставляет целую подборку результатов, которые можно быстро изучить прямо на странице поиска.
3. StartPage
Что это
Интересный поисковик, который объединяет в себе лучшее из двух миров. В отличие о конкурентов, использующих собственные движки, которые откровенно слабее крупных игроков, StartPage берёт выдачу из Google. Важный момент: при этом он обезличивает все ваши запросы, сохраняя анонимность.
Чем лучше
Зачем это вам
Попробуйте, если результаты альтернативных поисковиков не устраивают, а со слежкой Google вы мириться не готовы.
4. Swisscows
Что это
Швейцарский сервис, в основе которого лежит семантический поиск на основе машинного обучения. Искусственный интеллект определяет контекст поискового запроса и угадывает, что на самом деле вы ищете.
Swisscows сотрудничает с Bing и использует их индексированную выдачу в дополнение к своей собственной. Монетизация осуществляется за счёт рекламы, которая основывается исключительно на поисковых запросах.
Чем лучше
Ключевая особенность сервиса — в семантическом алгоритме, который делает поиск интеллектуальным. Swisscows не хранит файлы cookies, не отслеживает ваше поведение и сохраняет анонимность — вы всегда остаётесь гостем.
Зачем это вам
Swisscows пригодится, если вам нужен честный, безопасный и анонимный поисковик с собственным индексом.
5. Dogpile
Что это
Метапоисковик Dogpile выводит комбинированный список результатов из поисковых выдач Google, Yahoo и других популярных систем.
Чем лучше
Во-первых, Dogpile отображает меньше рекламы. Во-вторых, сервис использует особый алгоритм, чтобы находить и показывать лучшие результаты из разных поисковиков. Как утверждают разработчики Dogpile, их система формирует самую полную выдачу во всём интернете.
Зачем это вам
Если вы не можете найти информацию в Google или другом стандартном поисковике, попробуйте обнаружить её сразу в нескольких поисковиках с помощью Dogpile.
6. BoardReader
Что это
BoardReader — система для текстового поиска по форумам, сервисам вопросов и ответов и другим сообществам.
Чем лучше
Зачем это вам
BoardReader может пригодиться пиарщикам и другим специалистам в области медиа, которых интересует мнение массовой аудитории по тем или иным вопросам.
7. FindSounds
Что это
FindSounds — ещё один специализированный поисковик. Ищет в открытых источниках различные звуки: дом, природа, машины, люди и так далее. Сервис не поддерживает запросы на русском языке, но есть внушительный список русскоязычных тегов, по которым можно выполнять поиск.
Чем лучше
В выдаче только звуки и ничего лишнего. В настройках можно выставить желаемый формат и качество звучания. Все найденные записи доступны для скачивания. Имеется поиск по образцу.
Зачем это вам
Если вам нужно быстро найти звук мушкетного выстрела, удары дятла-сосуна или крик Гомера Симпсона, то этот сервис для вас. И это мы выбрали только из доступных русскоязычных запросов. На английском спектр ещё шире.
Если серьёзно, специализированный сервис предполагает специализированную аудиторию. Но вдруг и вам пригодится?
8. Wolfram|Alpha
Что это
Чем лучше
Зачем это вам
Текст был обновлён в феврале 2022 года.
Сервисы с наибольшим количеством вакансий.

1. HeadHunter
Один из популярнейших сайтов, на котором размещён почти 1 миллион вакансий. Причём есть варианты и для высококвалифицированных специалистов, и для людей без опыта или студентов. На hh.ru удобная форма составления резюме. Документ впоследствии можно сохранить и использовать вне площадки.
2. SuperJob
По заверениям создателей сайта, с ними сотрудничают 2,2 миллиона работодателей. Также здесь можно найти много советов для кандидатов, как эффективнее искать работу, откликаться на предложения и так далее.
3. «Работа.ру»
На сайте представлены вакансии 760 тысяч работодателей. Причём они ориентированы на любой сегмент поиска.
4. «Работа в России»
Это сайт Роструда, через который можно подать заявку на биржу труда. Здесь же размещены вакансии, которые предлагают тем, кто зарегистрирован как безработный. Откликаться на них можно всем, но общая направленность сайта всё же влияет на то, кого ищут. Так что он подойдёт для тех, кто ищет работу в государственных и муниципальных учреждениях — например, учителем или врачом. Также здесь много вакансий по рабочим специальностям или для людей без квалификации.
5. «Авито. Работа»
На сайте размещено более 2,4 миллиона вакансий. Особенно много здесь вариантов для представителей рабочих профессий и мест, которые не требуют квалификации.
6. «Хабр. Карьера»
Сервис, ориентированный на поиск работы в IT-сфере. Среди прочего стоит отметить, что на сайте можно посмотреть среднюю зарплату по вашей специальности и определиться с запросами.
7. «Город работ»
Это агрегатор, который собирает вакансии с других сайтов. Может быть удобен для тех, кто не хочет мониторить разные площадки самостоятельно.
8. Remote-job.ru
Сайт специализируется на вакансиях для удалённой работы. Здесь много предложений проектного сотрудничества, но не только. Вполне возможны и варианты найма по трудовому договору.
9. «Вакансии для хороших людей»
Сайт ориентирован на людей творческих специальностей: медиа, креатив, дизайн, PR и так далее.
10. «Зарплата.ру»
Ещё один сайт с большим количеством вакансий в разных сферах.
11. «Работа для вас»
Это сайт газеты «Работа для вас». Однако листать страницы в интернете удобнее, чем бумажное издание.
Работа в Москве
- Свежие вакансии на www.superjob.ru в Москве от прямых работодателей, агентств, центров занятости.
- В нашей базе содержатся предложения для всех специальностей: с опытом и без опыта работы, подработка с ежедневной оплатой, поиск удаленной работы, работа вахтовым методом.
- Все самые популярные вакансии на сегодня, в городе Москва: Грузчик, Водитель, Курьер, Разнорабочий, Продавец-кассир, Продавец-консультант, Повар, Кладовщик, Охранник, Бухгалтер, Продавец, Подсобный рабочий и другие профессии.
- Актуальные объявления о работе в вашем городе! Удобный поиск свежих вакансий на сегодня!
Работодателям
Работодателям доступна база резюме кандидатов в Москве, которая обновляется ежедневно.
- У нас вы найдете соискателей с нужными навыками и опытом работы, пригласите их на собеседование и выберете подходящего сотрудника.
- Более 800 000 объявлений о вакансиях и резюме. Сайт SuperJob помогает находить работу и подобрать персонал!
Соискателям
- Создавайте резюме бесплатно и откликайтесь на свежие вакансии!
- Общайтесь с работодателем через чат, не обязательно звонить!
- Просматривайте статус рассмотрения вашего резюме и получайте приглашения на собеседование из личного кабинета!
В этой статье речь пойдет о крутых инди поисковиках, которые могут составить конкуренцию поисковым гигантам, а также удовлетворить вкусы как утонченного мусьё, так и идейного борца за личную жизнь.
CC Search
CC Search заточен под то, чтобы искать материал не обремененный авторскими правами. Так что если ты контент мейкер, особенно начинающий и денег на платные подписки пока нет, а годноты таки хочется, то этот поисковик — то, что надо.
Если нужно изображение для поста в блоге или что-то ещё, то можно смело брать любые материалы из выдачи, не беспокоясь о том, что за тобой придет кто надо с повесткой в суд за нарушение авторских прав.
Работает CC Search довольно прямолинейно: он извлекает результаты с таких платформ, как Brooklyn Museum, Wikimedia и Flickr и отображает результаты, помеченные как материал Creative Commons.
В панели слева можно выбрать тип лицензии по которой будет фильтроваться контент, ну и прочие стандартные фильтры — тип файла, размер, также можно фильтровать по источникам добычи.
SwissCows
«Швейцарские коровы» — это уникальный поисковик с милым швейцарским дизайном и запахом сыра. Oн позиционирует себя как семантическую поисковую систему для семейного пользования и использует искусственный интеллект для определения контекста пользовательского запроса.
Они так же гордятся тем, что уважают частную жизнь пользователей, никогда не собирая, не сохраняя и не отслеживая данные. Что ж, надеюсь их защита имеет меньше дыр, чем их сыр.
DuckDuckGo
Поисковик «УткаУткаИди» не собирает и не хранит твои личные данные, по крайней мере так они говорят (кря).
Это означает, что ты можешь спокойно выполнять поиск, не беспокоясь о том, что твой личный ФСБшник узнает, что ты все ещё ищешь адрес того деда мороза, которому рассказывал стишок когда тебе было 9 и почему поиск продолжает выдавать адрес мордовской колонии номер 17.
В любом случае, DuckDuckGo — идеальный выбор для тех, кто хочет сохранить свои привычки просмотра и личную информацию конфиденциальной, если ты понимаешь о чём я.
StartPage
StartPage предоставляет ответы от Google, что делает его идеальным выбором для тех, кто предпочитает результаты поиска Google, но не хочет, чтобы их история поиска отслеживалась и сохранялась.
Он также включает в себя генератор URL, прокси-сервис и поддержку HTTPS.
Генератор URL особенно полезен, потому что он устраняет необходимость собирать куки.
Вместо этого он запоминает настройки таким образом, чтобы обеспечить конфиденциальность.
SearchEncrypt
SearchEncrypt — это поисковая система, которая использует локальное шифрование для обеспечения конфиденциальности запросов.
Информация для реальных ценителей — поисковик использует комбинацию методов шифрования, которые включают шифрование Secure Sockets Layer и шифрование AES-256.
Когда ты вводишь запрос, Search Encrypt извлекает результаты из своей сети партнёров по поиску и передает запрашиваемую информацию.
Интересная особенность Search Encrypt заключается в том, что после 30 минут бездействия, твои поисковые запросы и настройки обнуляются, поэтому никто не узнает что ты там искал, печатая одной рукой.
Search Encrypt — Выбор настоящего параноика.
Gibiru
Календарь Майя предсказывал столкновение Земли с планетой Нибиру, но в итоге Земля столкнулась с Gibiru.
Встречайте — приватный поиск, нефильтрованное. По заверениям создателей — абсолютно анонимный поиск без куков, ретаргетинга, и перепродажи личных данных.
Все их доходы генерируются через сбор комиссии, когда пользователи покупают или продают через их поисковик. Также имеется мобильный аналог — приложение Wormhole и ExpressVPN, видимо, от их друганов.
OneSearch
В январе 2020 года Verizon Media, так называется подразделение Verizon Communications, то есть Bell Corporation, после того, как её раскололи и перекрасили — запустила поисковую систему OneSearch, ориентированную на конфиденциальность.
Они заявляют что в их поисковике:
Нет отслеживания файлов cookie, ретаргетинга или личного профилирования.
Нет обмена персональными данными с рекламодателями.
Нет хранения истории поиска пользователей.
Но есть:
Беспристрастные, нефильтрованные и зашифрованные результаты поиска.
По сути, это еще один поисковик, пытающийся позиционировать себя не похожим на Google, тот в свою очередь не скрывает что проводит сбор данных, однако, что твориться в OneSearch на самом деле — неизвестно.
Wiki.com
Это поисковой агрегатор, выуживающий информацию с википедии и с тысяч различных wiki по всему интернету.
Как по мне, то выглядит достаточно криво и небезопасно. Но если в тебе жив дух коммунны википедии, ты уже занёс пожертвование её создателю и добавил последние правки в статью про канцелярскую скрепку, то возможно тебе зайдёт и это. Ну или если твою жену зовут Вика.
Boardreader
Если посреди ночи ты не можешь уснуть оттого, что наконец придумал, что бы ты ответил тому засранцу на форуме по арктическим пингвинам 5 лет назад, то этот поисковик поможет тебе разыскать нужную ветку, ведь ищет он как раз по различным форумам, бордам и ответам мейл.ру.
Как известно, люди не всегда сдержаны в общении между собой, особенно в интернете, так что если тебе вздумалось найти примеры эпичнейших боев по переписке уважаемых и не только граждан, то этот поисковик готов копаться в интернет-отходах после срачей в комментах.
giveWater
Пока Джеф Безос наслаждается званием человека, собравшего больше всех нулей на своем банковском счету, два хипана из Нью Йорка сделали «дайВоду» — поисковик, который они сами описывают как «социально значимый».
Итак, как он работает:
Ты используешь giveWater, для поиска, к примеру, материала для своего диплома.
Платные поисковые объявления генерируют доход для giveWater.
giveWater распределяет прибыль от этих объявлений между своими партнерами — благотворительными фондами
Фонды используют пожертвованные средства для обеспечения чистой водой.
Ecosia
Поисковик из Германии, который отдает 80% своих доходов на посадку деревьев и работающий по схожему с giveWater принципу, ставя социально значимые проекты на первое место перед прибылью для акционеров и инвесторов.
Когда в 2019 PornHub пообещал начать сажать деревья за просмотры видео, пользователи незамедлительно предложили открывать PornHub в Ecosia, дабы озеленить планету с ещё большей скоростью. Как говорится: «ствол за ствол».
Ekoru
Еще один озеленительный проект, который утверждает, что их сервера также работают на зеленой энергии.
Ekoru использует доходы для очистки океана, предотвращения гибели лесов и изменения климата в худшую сторону. А также дает прохладу, влажность и, скорее всего, силу земли.
Slideshare
Не совсем отдельный поисковик, скорее фича платформы LinkedIn, с помощью которого можно искать, внезапно — слайды и презентации. Так что, бери бизнес ланч и врубай яппи-диафильм про то, как менялись предпочтения населения Среднего Запада относительно сухих завтраков.
Wayback Machine
Он же — интернет архив. Хочешь узнать, не был ли сегодняшний божий одуванчик в прошлом злым бармалеем, пытающимся замести следы, или просто ностальгируешь по тому, что любимый сайт выглядел раньше не то, что сейчас?
Тогда тебе сюда. Этот поисковик делает снимки интернет ресурсов в определенный момент времени, в которое ты и можешь отправиться.
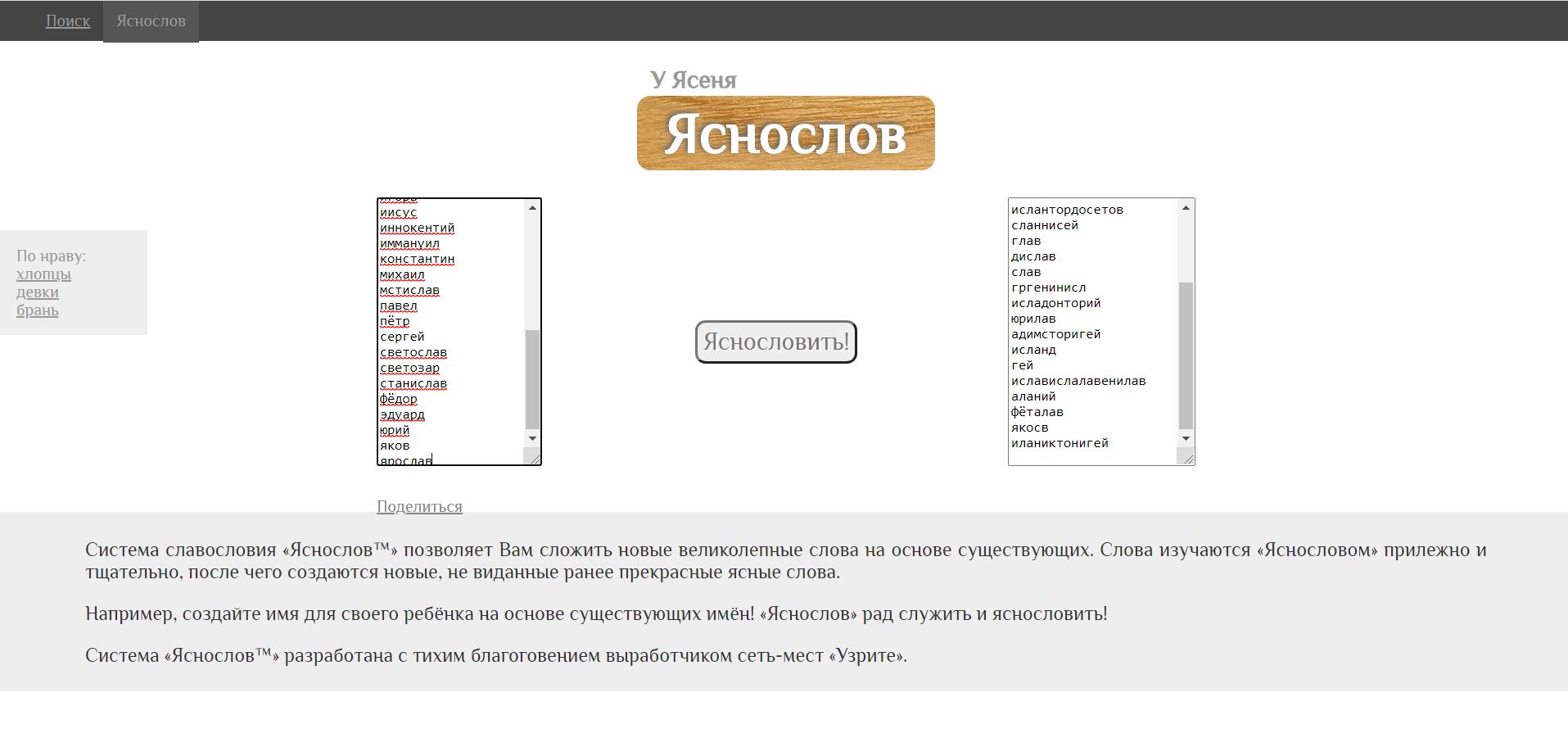
У Ясеня
Как известно, настоящие мужики не пользуются гуглом, они спрашивают у ясеня. Но поскольку неспешные беседы с деревом могут перерасти в поездку в тихое место с мягкими стенами, артель, по всей видимости, православных разработчиков создала былинный поисковик уясеня.рф
К сожалению Ясень в основном качает головой и не выдает реальные результаты, дерево все-таки.
Например, можно спросить у Ясеня имя своего будущего чада и сказочный пилматериал съяснословит что-то вроде «Енотия».
Судя по дизайну, пилили его пока у авторов не выветрилась брага.
Но мы желаем творцам плодотворного труда, дабы порадовать люд православный новыми поделками скоморошными, например, подсчет годочков бытия с помощью кукушки.
Пиши в комментариях свои личные предпочтения или если я упустил кого-то достойного внимания. Аве!
Можете воспользоваться вариантами выбора на данной странице для задания узких параметров поиска. Для этого необходимо заполнить поля, необходимые для выполнения текущего запроса.
К вашим услугам кеш поисковиков, интернет-архивы и не только.

Если, открыв нужную страницу, вы видите ошибку или сообщение о том, что её больше нет, ещё не всё потеряно. Мы собрали сервисы, которые сохраняют копии общедоступных страниц и даже целых сайтов. Возможно, в одном из них вы найдёте весь пропавший контент.
Поисковые системы
Поисковики автоматически помещают копии найденных веб‑страниц в специальный облачный резервуар — кеш. Система часто обновляет данные: каждая новая копия перезаписывает предыдущую. Поэтому в кеше отображаются хоть и не актуальные, но, как правило, довольно свежие версии страниц.
1. Кеш Google
Чтобы открыть копию страницы в кеше Google, сначала найдите ссылку на эту страницу в поисковике с помощью ключевых слов. Затем кликните на стрелку рядом с результатом поиска и выберите «Сохранённая копия».
2. Кеш «Яндекса»
Введите в поисковую строку адрес страницы или соответствующие ей ключевые слова. После этого кликните по стрелке рядом с результатом поиска и выберите «Сохранённая копия».
3. Кеш Bing
В поисковике Microsoft тоже можно просматривать резервные копии. Наберите в строке поиска адрес нужной страницы или соответствующие ей ключевые слова. Нажмите на стрелку рядом с результатом поиска и выберите «Кешировано».
4. Кеш Yahoo
Если вышеупомянутые поисковики вам не помогут, проверьте кеш Yahoo. Хоть эта система не очень известна в Рунете, она тоже сохраняет копии русскоязычных страниц. Процесс почти такой же, как в других поисковиках. Введите в строке Yahoo адрес страницы или ключевые слова. Затем кликните по стрелке рядом с найденным ресурсом и выберите Cached.
Специальные архивные сервисы
Указав адрес нужной веб‑страницы в любом из этих сервисов, вы можете увидеть одну или даже несколько её архивных копий, сохранённых в разное время. Таким образом вы можете просмотреть, как менялось содержимое той или иной страницы. В то же время архивные сервисы создают новые копии гораздо реже, чем поисковики, из‑за чего зачастую содержат устаревшие данные.
Чтобы проверить наличие копий в одном из этих архивов, перейдите на его сайт. Введите URL нужной страницы в текстовое поле и нажмите на кнопку поиска.
1. Wayback Machine (Web Archive)
Сервис Wayback Machine, также известный как Web Archive, является частью проекта Internet Archive. Здесь хранятся копии веб‑страниц, книг, изображений, видеофайлов и другого контента, опубликованного на открытых интернет‑ресурсах. Таким образом основатели проекта хотят сберечь культурное наследие цифровой среды.
2. Arhive.Today
Arhive.Today — аналог предыдущего сервиса. Но в его базе явно меньше ресурсов, чем у Wayback Machine. Да и отображаются сохранённые версии не всегда корректно. Зато Arhive.Today может выручить, если вдруг в Wayback Machine не окажется копий необходимой вам страницы.
3. WebCite
Ещё один архивный сервис, но довольно нишевый. В базе WebCite преобладают научные и публицистические статьи. Если вдруг вы процитируете чей‑нибудь текст, а потом обнаружите, что первоисточник исчез, можете поискать его резервные копии на этом ресурсе.
Другие полезные инструменты
Каждый из этих плагинов и сервисов позволяет искать старые копии страниц в нескольких источниках.
1. CachedView
Сервис CachedView ищет копии в базе данных Wayback Machine или кеше Google — на выбор пользователя.
2. CachedPage
Альтернатива CachedView. Выполняет поиск резервных копий по хранилищам Wayback Machine, Google и WebCite.
3. Web Archives
Это расширение для браузеров Chrome и Firefox ищет копии открытой в данный момент страницы в Wayback Machine, Google, Arhive.Today и других сервисах. Причём вы можете выполнять поиск как в одном из них, так и во всех сразу.

![]()

Наверное, многие когда-нибудь задумывались, как сделать поиск на сайте? Безусловно, для крупных сайтов с большим количеством контента поиск является просто незаменимой вещью. В большинстве случаев пользователь, впервые посетив Ваш сайт в поисках чего-либо важного, не станет разбираться в навигационных панелях, выпадающих меню и прочих элементах навигации, а в спешке попытается найти что-нибудь похожее на поисковую строку. И если такой роскоши на сайте не окажется, либо он не справится с поисковым запросом, то посетитель просто закроет вкладку. Но статья не о значении поиска для сайта и не о психологии посетителей. Я расскажу, как реализовать небольшой алгоритм полнотекстового поиска, который, надеюсь, избавит начинающих разработчиков от головной боли.
У читателя может возникнуть вопрос: зачем писать все с нуля, если все уже давно написано? Да, у крупных поисковиков есть API, есть такие клевые проекты, как Sphinx и Apache Solr. Но у каждого из этих решений есть свои преимущества и недостатки. Пользуясь услугами поисковиков, типа Google и Яндекс, Вы получите множество плюшек, таких как мощный морфологический анализ, исправление опечаток и ошибок в запросе, распознавание неверной раскладки клавиатуры, однако без ложки дегтя тут не обойдется. Во первых, такой поиск не интегрируется в структуру сайта — он внешний, и Вы не сможете указать ему, какие данные наиболее важны, а какие не очень. Во вторых, содержимое сайта индексируется только с определенным интервалом, который зависит от выбранного поисковика, так что если на сайте что-нибудь обновится, придется дожидаться момента, когда эти изменения попадут в индекс и станут доступными в поиске. У Sphinx и Apache Solr дела с интеграцией и индексированием гораздо лучше, но не каждый хостинг позволит из запустить.
Ничто не мешает написать поисковый механизм самостоятельно. Предполагается, что сайт работает на PHP в связке с каким-нибудь сервером баз данных, например MySQL. Давайте сначала определимся, что требуется от поиска на сайте?
- Поиск с учетом языковой морфологии. Независимо от падежа, окончания и
других прелестей великого и могучего языка поиск должен находить то, что нужно
пользователю. Другими словами, «яблок», «яблока», «яблоки» — это формы одного и того
же слова «яблоко», что нужно учитывать в поисковом алгоритме. Одним из способов
достижения данной цели является приведение каждого слова поискового запроса и слов
содержимого сайта к базовой форме. - Возможность указать контекст поиска. То есть, возможность самостоятельно выбрать
контент сайта, в пределах которого будет работать поисковый алгоритм, а также определить
значимость для каждого из пределов. Например, рассмотрим интернет-магазин. Предполагается,
что поисковый запрос чаще всего будет содержать название искомой продукции, поэтому поиск по
названиям товара будет иметь наивысший приоритет. В качестве следующего приоритета можно
выбрать поиск по свойствам товаров, затем поиск по описанию. - Индексирование содержимого сайта. Представьте ситуацию: одновременно около 30 человек
выполняют поисковые запросы. Сервер принимает каждое соединение, управление потоком
передается интерпретатору PHP. При каждом запросе заново инициализируется поисковый
движок, заново перерывается содержимое сайта… Сложно сказать, сколько времени и
ресурсов потребуется, чтобы обработать все эти запросы. Именно для того, чтобы не
делать одну и ту же работу по сто раз, была придумана технология индексирования.
Индексирование выполняется только при изменении или добавлении содержимого сайта,
а поиск выполняется уже по индексу, а не по содержимому. - Механизм ранжирования. Ранжирование результатов поиска — это сортировка результатов поиска, выполняемая на основе оценки значимости найденных данных. Например, в каком-нибудь блоге выполняется поисковый запрос «космос». Данное слово содержится в двух статьях: в первой 16 раз, во второй — 5 раз. Вероятнее всего, первая статья будет иметь большее значение для инициатора поиска. Также каждой разновидности содержимого сайта при индексировании задается определенный коэффициент, который будет влиять на его позиции в поисковой выдаче.
Теперь пару слов о том, что нам предстоит реализовать:
- морфологический анализатор,
- алгоритм ранжирования,
- алгоритм индексирования,
- алгоритм поиска.
В конце статьи будет показан пример реализации поиска на примере простого интернет-магазина. Тем, кому лень все это изучать и просто нужен готовый поисковик, можно смело забирать движок из репозитория GitHub FireWind.
Принцип работы
Со стороны бэкенда поиск работает так:
- содержимое сайта индексируется,
- пользователь присылает запрос,
- из запроса исключаются служебные части речи,
- получившаяся строка разбивается на массив слов, переведенных в базовую форму,
- поиск каждого слова полученного массива осуществляется в индексе,
- результаты поиска ранжируются, сортируются и отдаются пользователю.
Подготовка
Наш проект будет состоять из ядра, где будут собраны все жизненно необходимые функции, а также модуля морфологического анализа и обработки текста. Для начала создадим корневую папку проекта firewind, а в ней создадим файл core.php — он и будет ядром.
$ mkdir firewind
$ cd firewind
$ touch core.php
Теперь вооружаемся своим любимым текстовым редактором и подготавливаем каркас:
<?php
class firewind {
public $VERSION = "1.0.0";
function __construct() {
// Инициализатор //
}
}
?>
Тут мы создали основной класс, который можно будет использовать на Ваших сайтах. На этом подготовительная часть заканчивается, пора двигаться дальше.
Морфологический анализатор
Нужна библиотека и словарь для нее. Все это добро можно найти тут. Библиотека находится в одноименной папке «phpmorphy», словари расположены в «phpmorphy-dictionaries». Скачиваем последние версии в корневую папку проекта и распаковываем:
# Распаковываем библиотеку
$ unzip phpmorphy-0.3.7.zip
$ mv phpmorphy-0.3.7 phpmorphy
# Распаковываем словарь в phpmorphy/dicts
$ unzip morphy-0.3.x-ru_RU-withjo-utf-8.zip -d phpmorphy/dicts/
# Удаляем исходные архивы
$ rm phpmorphy-0.3.7.zip morphy-0.3.x-ru_RU-withjo-utf-8.zip
Отлично! Библиотека готова к использованию. Пришло время написать «оболочку», которая абстрагирует работу с phpMorphy. Для этого создадим еще один файл morphyus.php в корневой директории:
<?php
require_once __DIR__.'/phpmorphy/src/common.php';
class morphyus {
private $phpmorphy = null;
private $regexp_word = '/([a-zа-я0-9]+)/ui';
private $regexp_entity = '/&([a-zA-Z0-9]+);/';
function __construct() {
$directory = __DIR__.'/phpmorphy/dicts';
$language = 'ru_RU';
$options[ 'storage' ] = PHPMORPHY_STORAGE_FILE;
// Инициализация библиотеки //
$this->phpmorphy = new phpMorphy( $directory, $language, $options );
}
/**
* Разбивает текст на массив слов
*
* @param {string} content Исходный текст для выделения слов
* @param {boolean} filter Активирует фильтрацию HTML-тегов и сущностей
* @return {array} Результирующий массив
*/
public function get_words( $content, $filter=true ) {
// Фильтрация HTML-тегов и HTML-сущностей //
if ( $filter ) {
$content = strip_tags( $content );
$content = preg_replace( $this->regexp_entity, ' ', $content );
}
// Перевод в верхний регистр //
$content = mb_strtoupper( $content, 'UTF-8' );
// Замена ё на е //
$content = str_ireplace( 'Ё', 'Е', $content );
// Выделение слов из контекста //
preg_match_all( $this->regexp_word, $content, $words_src );
return $words_src[ 1 ];
}
/**
* Находит леммы слова
*
* @param {string} word Исходное слово
* @param {array|boolean} Массив возможных лемм слова, либо false
*/
public function lemmatize( $word ) {
// Получение базовой формы слова //
$lemmas = $this->phpmorphy->lemmatize( $word );
return $lemmas;
}
}
?>
Пока реализовано только два метода. get_words разбивает текст на массив слов, фильтруя при этом HTML-теги и сущности типа “ ”. Метод lemmatize возвращает массив лемм слова, либо false, если таковых не нашлось.
Механизм ранжирования на уровне морфологии
Давайте остановимся на такой единице языка, как предложение. Наиболее важной частью предложения является основа в виде подлежащего и/или сказуемого. Чаще всего подлежащее выражается существительным, а сказуемое глаголом. Второстепенные члены в основном употребляются для уточнения смысла основы. В разных предложениях одни и те же части речи порой имеют совершенно разное значение, и наиболее точно оценить это значение в контексте текста сегодня может только человек. Однако программно оценить значение какого-либо слова все-таки можно, хоть и не так точно. При этом алгоритм ранжирования должен опираться на так называемый профиль текста, который определяется его автором. Профиль представляет из себя ассоциативный массив, ключами которого являются части речи, а значениями соответственно ранг (или вес) каждой из них. Пример профиля я покажу в заключении, а пока попробуем перевести эти размышления на язык PHP, добавив еще один метод к классу morphyus:
<?php
require_once __DIR__.'/phpmorphy/src/common.php';
class morphyus {
private $phpmorphy = null;
private $regexp_word = '/([a-zа-я0-9]+)/ui';
private $regexp_entity = '/&([a-zA-Z0-9]+);/';
// ... //
/**
* Оценивает значимость слова
*
* @param {string} word Исходное слово
* @param {array} profile Профиль текста
* @return {integer} Оценка значимости от 0 до 5
*/
public function weigh( $word, $profile=false ) {
// Попытка определения части речи //
$partsOfSpeech = $this->phpmorphy->getPartOfSpeech( $word );
// Профиль по умолчанию //
if ( !$profile ) {
$profile = [
// Служебные части речи //
'ПРЕДЛ' => 0,
'СОЮЗ' => 0,
'МЕЖД' => 0,
'ВВОДН' => 0,
'ЧАСТ' => 0,
'МС' => 0,
// Наиболее значимые части речи //
'С' => 5,
'Г' => 5,
'П' => 3,
'Н' => 3,
// Остальные части речи //
'DEFAULT' => 1
];
}
// Если не удалось определить возможные части речи //
if ( !$partsOfSpeech ) {
return $profile[ 'DEFAULT' ];
}
// Определение ранга //
for ( $i = 0; $i < count( $partsOfSpeech ); $i++ ) {
if ( isset( $profile[ $partsOfSpeech[ $i ] ] ) ) {
$range[] = $profile[ $partsOfSpeech[ $i ] ];
} else {
$range[] = $profile[ 'DEFAULT' ];
}
}
return max( $range );
}
}
?>
Индексирование содержимого сайта

Как уже говорилось выше, индексирование заметно ускоряет выполнение поискового запроса, так как поисковому движку не нужно обрабатывать контент каждый раз заново — поиск выполняется по индексу. Но что же все-таки происходит при индексировании? Если по порядку, то:
- Сначала из текста формируется массив слов, и делается это с помощью метода get_words.
- Согласно профилю, из текста отбрасываются незначимые части речи.
- Значимые оцениваются по пятибальной шкале, с помощью метода weigh.
- Для каждого сова выполняется поиск лемм, иначе говоря базовых форм.
- Рассчитывается количество повторений каждого слова и суммарный ранг.
- Все данные записываются в объект и в виде JSON записываются в базу данных.
В результате получается объект следующего формата:
{
"range" : "<коэффициент значимости индексируемых данных>",
"words" : [
// Одно из слов //
{
"source" : "<базовая версия слова>",
"range" : "<суммарный ранг>",
"count" : "<количество повторений данного слова в тексте>",
"weight" : "<ранг на основе части речи>",
"basic" : [
// Варианты лемм слова //
]
}
]
}
Пишем инициализатор и первый метод ядра поискового движка:
<?php
require_once 'morphyus.php';
class firewind {
public $VERSION = "1.0.0";
private $morphyus;
function __construct() {
$this->morphyus = new morphyus;
}
/**
* Выполняет индексирование текста
*
* @param {string} content Текст для индексирования
* @param {integer} [range] Коэффициент значимости индексируемых данных
* @return {object} Результат индексирования
*/
public function make_index( $content, $range=1 ) {
$index = new stdClass;
$index->range = $range;
$index->words = [];
// Выделение слов из текста //
$words = $this->morphyus->get_words( $content );
foreach ( $words as $word ) {
// Оценка значимости слова //
$weight = $this->morphyus->weigh( $word );
if ( $weight > 0 ) {
// Количество слов в индексе //
$length = count( $index->words );
// Проверка существования исходного слова в индексе //
for ( $i = 0; $i < $length; $i++ ) {
if ( $index->words[ $i ]->source === $word ) {
// Исходное слово уже есть в индексе //
$index->words[ $i ]->count++;
$index->words[ $i ]->range =
$range * $index->words[ $i ]->count * $index->words[ $i ]->weight;
// Обработка следующего слова //
continue 2;
}
}
// Если исходного слова еще нет в индексе //
$lemma = $this->morphyus->lemmatize( $word );
if ( $lemma ) {
// Проверка наличия лемм в индексе //
for ( $i = 0; $i < $length; $i++ ) {
// Если у сравниваемого слова есть леммы //
if ( $index->words[ $i ]->basic ) {
$difference = count(
array_diff( $lemma, $index->words[ $i ]->basic )
);
// Если сравниваемое слово имеет менее двух отличных лемм //
if ( $difference === 0 ) {
$index->words[ $i ]->count++;
$index->words[ $i ]->range =
$range * $index->words[ $i ]->count * $index->words[ $i ]->weight;
// Обработка следующего слова //
continue 2;
}
}
}
}
// Если в индексе нет ни лемм, ни исходного слова, //
// значит пора добавить его //
$node = new stdClass;
$node->source = $word;
$node->count = 1;
$node->range = $range * $weight;
$node->weight = $weight;
$node->basic = $lemma;
$index->words[] = $node;
}
}
return $index;
}
}
?>
Теперь при добавлении или изменении данных в таблицах достаточно просто вызвать данную функцию, чтобы проиндексировать их, но это не обязательно: индексирование может быть и отложенным. Первым аргументом метода make_index является исходный текст, вторым — коэффициент значимости индексируемых данных. Ранг каждого слова, кстати, расчитывается по формуле:
<?php
$range = <коэффициент значимости> * <ранг на основе части речи> * <количество повторений>;
// В коде это выглядит так: //
$index->words[ $i ]->range = $range * $index->words[ $i ]->count * $index->words[ $i ]->weight;
?>
Хранение индексированных данных
Очевидно, что индекс нужно где-нибудь хранить, да еще и привязать к исходным данным. Наиболее подходящим местом для них будет база данных. Если индексируется содержимое файлов, то можно создать отдельную таблицу в базе данных, которая будет содержать индекс название каждого файла, а для содержимого, которое уже хранится в базе, можно добавить еще одно поле типа в структуру таблиц. Такой подход позволит разделять типы содержимого при поиске, например, названия и описание статей в случае блога.
Нерешенным остался лишь вопрос формата индексированного содержимого, ведь make_index возвращает объект, и так просто в базу данных или файл его не запишешь. Можно использовать JSON и хранить его в полях типа LONGTEXT, можно BSON или CBOR, используя тип данных LONGBLOB. Два последних формата позволяют представлять данные в более компактном виде, чем первый.
Как говорится, «хозяин — барин», так-что решать, где и как все будет храниться, Вам.
Benchmark
Давайте проверим, что у нас получилось. Я взял текст своей любимой статьи «Темная материя интернета», а именно содержимое узла #content html_format и сохранил его в отдельный файл.
<?php
require_once '../src/core.php';
$firewind = new firewind;
// Читаем исходный текст //
$source = file_get_contents( './source.html' );
// Засекаем время начала //
$begin_time = microtime( true );
echo "Indexing started: $begin_time\n";
// Индексирование //
$index = $firewind->make_index( $source );
// Засекаем время конца //
$finish_time = microtime( true );
echo "Indexing finished: $finish_time\n";
// Результаты //
$total_time = $finish_time - $begin_time;
echo "Total time: $total_time\n";
?>
Индексирование заняло около секунды:
$ php benchmark.php
Indexing started: 1417343592.3094
Indexing finished: 1417343593.5604
Total time: 1.2510349750519
Думаю, вполне неплохой результат.
Реализация поиска
<?php
require_once 'morphyus.php';
class firewind {
public $VERSION = "1.0.0";
private $morphyus;
// ... //
/**
* Выполняет поиск слов одного индексного объекта в другом
*
* @param {object} target Искомые данные
* @param {object} source Данные, в которых выполняется поиск
* @return {integer} Суммарный ранг на основе найденных данных
*/
public function search( $target, $index ) {
$total_range = 0;
// Перебор слов запроса //
foreach ( $target->words as $target_word ) {
// Перебор слов индекса //
foreach ( $index->words as $index_word ) {
if ( $index_word->source === $target_word->source ) {
$total_range += $index_word->range;
} else if ( $index_word->basic && $target_word->basic ) {
// Если у искомого и индексированного слов есть леммы //
$index_count = count( $index_word ->basic );
$target_count = count( $target_word ->basic );
for ( $i = 0; $i < $target_count; $i++ ) {
for ( $j = 0; $j < $index_count; $j++ ) {
if ( $index_word->basic[ $j ] === $target_word->basic[ $i ] ) {
$total_range += $index_word->range;
continue 2;
}
}
}
}
}
}
return $total_range;
}
}
?>
Реализация поиска на примере интернет-магазина
Допустим, информация о продаваемой продукции хранится в таблице production:
CREATE TABLE `production` (
`uid` INT NOT NULL AUTO_INCREMENT, -- Уникальный идентификатор
`name` VARCHAR(45) NOT NULL, -- Название продукта
`manufacturer` VARCHAR(45) NOT NULL, -- Производитель
`price` INT NOT NULL, -- Стоимость продукта
`keywords` TEXT NULL, -- Индекс ключевых слов
PRIMARY KEY ( `uid` )
);
SHOW COLUMNS FROM `production`;
+--------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-------------+------+-----+---------+-------+
| uid | int(11) | NO | PRI | NULL | |
| name | varchar(45) | NO | | NULL | |
| manufacturer | varchar(45) | NO | | NULL | |
| price | int(11) | NO | | NULL | |
| keywords | text | YES | | NULL | |
+--------------+-------------+------+-----+---------+-------+
А описание в таблице description:
CREATE TABLE `description` (
`uid` INT NOT NULL AUTO_INCREMENT, -- Уникальный идентификатор
`fid` INT NOT NULL, -- Внешний ключ для привязки описания к продукту
`description` LONGTEXT NOT NULL, -- Само описание
`index` TEXT NULL, -- Индексированное описание
PRIMARY KEY ( `uid` )
);
SHOW COLUMNS FROM `description`;
+-------------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+----------+------+-----+---------+-------+
| uid | int(11) | NO | PRI | NULL | |
| fid | int(11) | NO | | NULL | |
| description | longtext | NO | | NULL | |
| index | text | YES | | NULL | |
+-------------+----------+------+-----+---------+-------+
Поле production.keywords будет содержать индекс ключевых слов продукта, description.index будет содержать индексированное описание. И все это будут храниться в формате JSON.
Вот пример функции добавления нового продукта:
<?php
require_once 'firewind/core.php';
$firewind = new firewind;
$connection = new mysqli( 'host', 'user', 'password', 'database' );
if ( $connection->connect_error ) {
die( 'Cannot connect to database.' );
}
$connection->set_charset( 'UTF8' );
function add_product( $name, $manufacturer, $price, $description, $keywords ) {
global $firewind, $connection;
// Индексирование описания продукта //
$description_index = $firewind->make_index( $description );
$description_index = json_encode( $description_index );
// Индексирование ключевых слов //
$keywords_index = $firewind->make_index( $keywords, 2 );
$keywords_index = json_encode( $keywords_index );
// Подготовка запросов //
$production_query = $connection->prepare(
"INSERT INTO `production` ( `name`, `manufacturer`, `price`, `keywords` )
VALUES ( ?, ?, ?, ? )"
);
$description_query = $connection->prepare(
"INSERT INTO `description` ( `fid`, `description`, `index` )
VALUES ( LAST_INSERT_ID(), ?, ? )"
);
if ( !$production_query || !$description_query ) {
die( "Cannot prepare requests!\n" );
}
if (
// Биндинг параметров //
$production_query -> bind_param( 'ssis', $name, $manufacturer, $price, $keywords_index ) &&
$description_query -> bind_param( 'ss', $description, $description_index ) &&
// Выполнение запросов //
$production_query -> execute() &&
$description_query -> execute()
) {
// Если запросы выполнились успешно //
echo( "Product successfully added!\n" );
// Завершение запросов //
$production_query -> close();
$description_query -> close();
return true;
} else {
die( "An error occurred while executing query...\n" );
}
}
?>
Здесь поисковый механизм был интегрирован в функцию добавления нового продукта магазина. А теперь обработчик поисковых запросов:
<?php
require_once '../src/core.php';
$firewind = new firewind;
$connection = new mysqli( 'host', 'user', 'password', 'database' );
if ( $connection->connect_error ) {
die( 'Cannot connect to database.' );
}
$connection->set_charset( 'UTF8' );
// Поисковый запрос //
$query = isset( $_GET[ 'query' ] ) ? trim( $_GET[ 'query' ] ) : false;
if ( $query ) {
// Обработка поискового запроса //
$query_index = $firewind->make_index( $query );
// Получение данных //
$production = $connection->query("
SELECT p.`uid`, p.`name`, p.`keywords`, d.`index`
FROM `production` p, `description` d
WHERE p.`uid` = d.`uid`
");
if ( !$production ) {
die( "Cannot get production info.\n" );
}
// Выполнение поиска //
while ( $product = $production->fetch_assoc() ) {
// Распаковка индекса //
$keywords = json_decode( $product[ 'keywords' ] );
$index = json_decode( $product[ 'index' ] );
$range = $firewind->search( $query_index, $keywords );
$range += $firewind->search( $query_index, $index );
if ( $range > 0 ) {
$result[ $product[ 'uid' ] ] = $range;
}
}
// Если что-нибудь нашлось //
if ( isset( $result ) ) {
// Сортировка по убыванию //
arsort( $result );
// Вывод результатов //
$i = 1;
foreach ( $result as $uid => $range ) {
printf(
"#%d. Found product with id %d and range %d.\n",
$i++,
$uid,
$range
);
}
} else {
echo( "Sorry, no results found.\n" );
}
} else {
echo( "Query cannot be empty. Try again.\n" );
}
?>
Данный сценарий принимает поисковый запрос в виде GET-параметра query и выполняет поиск. В результате выводятся найденные продукты магазина.
Заключение
В статье был описан один из вариантов реализации поиска для сайта. Это самая первая его версия, поэтому буду только рад узнать Ваши замечания, мнения и пожелания. Присоединяйтесь к моему проекту на Github: https://github.com/axilirator/firewind. В планах добавить туда еще кучу всяких возможностей, вроде кэширования поисковых запросов, подсказок при вводе поискового запроса и алгоритма побуквенного сравнения, который поможет бороться с опечатками.
Всем спасибо за внимание, ну и с днем информационной безопасности!
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Какой поиск для сайта предпочитаете Вы?
Не использую поиск для сайта
Проголосовали 750 пользователей.
Воздержались 287 пользователей.
Это перепечатка статьи Ивана Никитина, которая в сентябре была опубликованна на нашем сайте Nomagic.ru. Данная статья содержит только постановку задачи и обсуждению возможных решений. Ссылки на статьи с описанием решения поставленной задачи c помощью LiveSearch API на ASP и PHP можно найти в конце статьи.
У любого современного сайта, на котором присутствуют более 5 – 10 страниц с контентом, должна быть поисковая система. Как бы хорошо мы не планировали навигационную панель, или каталог товаров/разделов сайта, все равно любые наши попытки интуитивно-понятной систематизации, в конечном итоге, будут непонятны 101-му пользователю сайта.
Хотите убедиться что это так? Вот несколько простых задач, попробуйте потратить на их решение несколько минут (все примеры взяты абсолютно случайно из списка лично мне знакомых и посещаемых мною сайтов. Эти примеры ни в коем случае не призваны приуменьшить качество этих ресурсов):
Следует ли продолжать? Думаю, вы уже согласны со мной. И точно также рассуждают разработчики сайтов, когда перед ними встает проблема создание поисковой системы. К сожалению, большинство разработчиков недооценивают сложность этого решения и полагают, что поиск можно свести (упрощенно) к SQL запросу:
SELECT * FROM products WHERE
title LIKE ‘%что-то%’
OR description LIKE ‘%что-то%’
- На сайте www.mts.ru найдите с помощью поиска кредитную форму оплаты разговоров, то есть как это оформить и как за разговоры платить… Какой запрос вы введете? «кредитная форма оплаты». Результат будет примерно таким:

- На сайте www.alfabank.ru найдите информацию об ипотечном кредитовании. Какой запрос вы введете? «Ипотека». Вот результат:

Легко заменить, что оба раза вы получили негативный результат. В первом случае вы не получили ничего, во втором – совершенно ненужную информацию (как вам понравилась ссылка на баннер про ипотеку?). Заметьте, оба раза неудачный поиск может заставить уйти клиента навсегда: я не стану переходить на MCT, так как там нет кредитной формы оплаты разговоров (на самом деле – есть!), и я не стану обращаться в Альфа-банк, так как не смог найти условий ипотечного кредитования (еще раз – это только примеры! Ничего личного!).
Как решить эту задачу?